This is by no means a complete guide, but a starting point for people who want to analyze Twitter networks with Gephi. I created it to help collaborators to explore Twitter networks of verified users. I published it to help other people who want to work with Gephi as well. Feel free to send me feedback or suggestions to add them to the guide.
Official Guides
https://gephi.org/users/install/
https://gephi.org/users/quick-start/
https://gephi.org/users/
Preparations
Gephi is powerful and even works nice with older computers. But as you work with bigger networks, the hardware will become your most limiting factor. In the Troubleshooting section I will give some performance tips. I still recommend at least 2GB of RAM. Ideally a dedicated GPU and a SSD.
Install Java
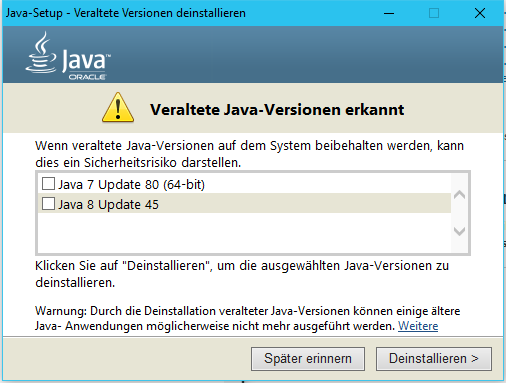
Gephi 0.9.1 supports Java 8. You should get the latest version available for your OS. You can test which version you have and get the latest one here.
If you want/need to use Gephi 0.8.2 as well, be sure to not uninstall Java 7, because Gephi 0.8.2 doesn’t work with Java 8. You may have to point Gephi to the appropriate Java version. Keep in mind that an outdated Java version is a security risk.
Install Gephi
- Download Gephi
- Install Gephi
- Open Gephi
Detailed Steps for Windows
Go here and download the latest version for your system. Gephi is available for Windows, OS X and Linux. The download is approximately 55MB big.
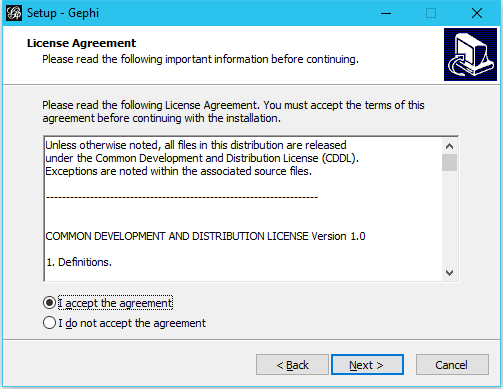
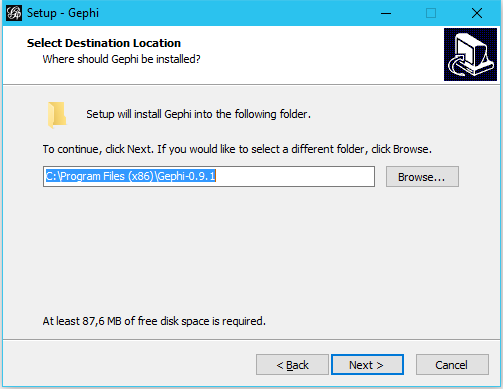
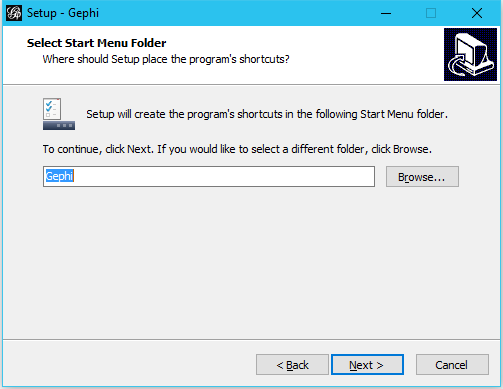
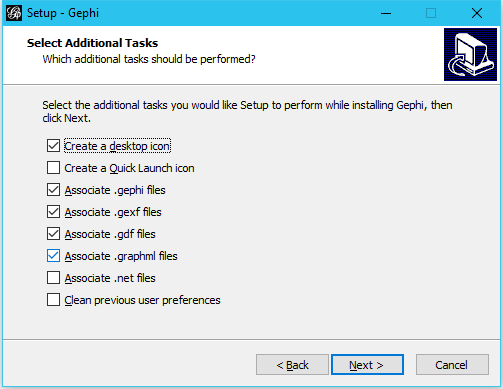
After downloading, open the downloaded file and go through the setup. The default settings should be fine. Feel free to change them to your needs.
The right mindset
Network visualization is messy. You get into technical difficulties and have to search the internet and peoples minds for solutions. The data itself is often inconsistent and you need to find ways to still get insights from it. The whole process is full of trial and error with many dead ends. There is no undo for most actions in network visualization. If you like a specific view on the data, better export it, because with the press of a button it may look totally different and even if you start with the same file and do the same things, the result will probably look different. It is possible to re-create certain views, but it takes a lot of time.
Get ready to get your hands dirty and spend hours without getting anywhere and keep going or starting fresh the next day. Over time it gets better. You will learn other peoples tricks and develop your own to get faster to useful results. You will experience the bliss of data that finally makes sense and the satisfaction when you share a beautiful visualization with others.
Keep going, share your process, save often and have fun.
Understanding the Interface of Gephi
In my expirience it’s much easier to experiment with a new tool, when you understand the basic interface. Gephi works slightly different than many other programs because of it threedifferent ways to work with the data.
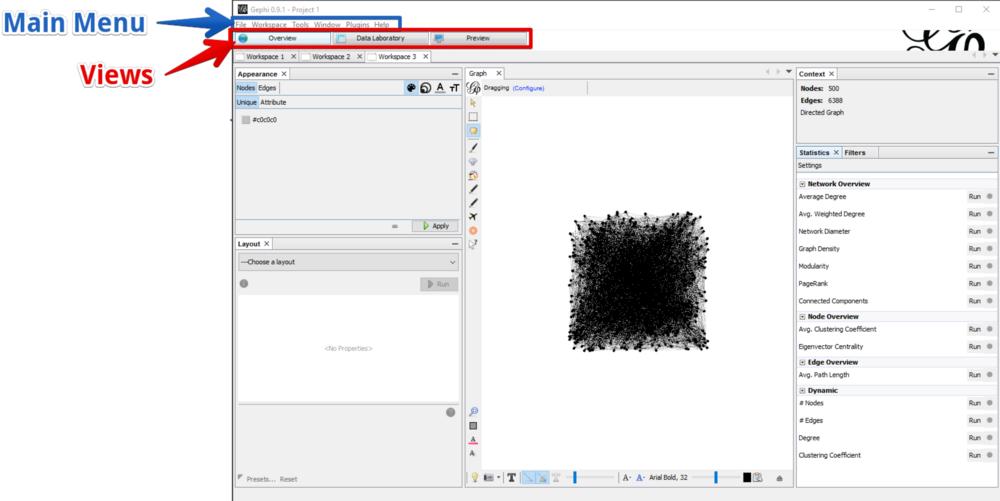
Three Different Views: Overview, Data Laboratory and Preview
Right below the main menu, Gephi has three buttons. You can click them at any time to switch between the different views. Each view can be customized by removing or adding windows, which could be names sections or areas as well. You find them in the main menu under the point “Window”. To remove something click on the x beside its name. To add it again, click on it in the main menu. The Overview is used to work interactively with the graph. The Data Laboratory gives you the raw data as a table. The Preview is used to generate beautiful looking versions of the graph. Each view accesses the same graph. If you change something in the Overview it’s changed in the Data Laboratory and the Preview as well.
Overview
This is where you spend most of the time interactively exploring a graph. You can define how nodes and edges look, use different algorithms to calculate the layout of the graph, use filters to work only with certain parts of the graph and calculate various statistics.
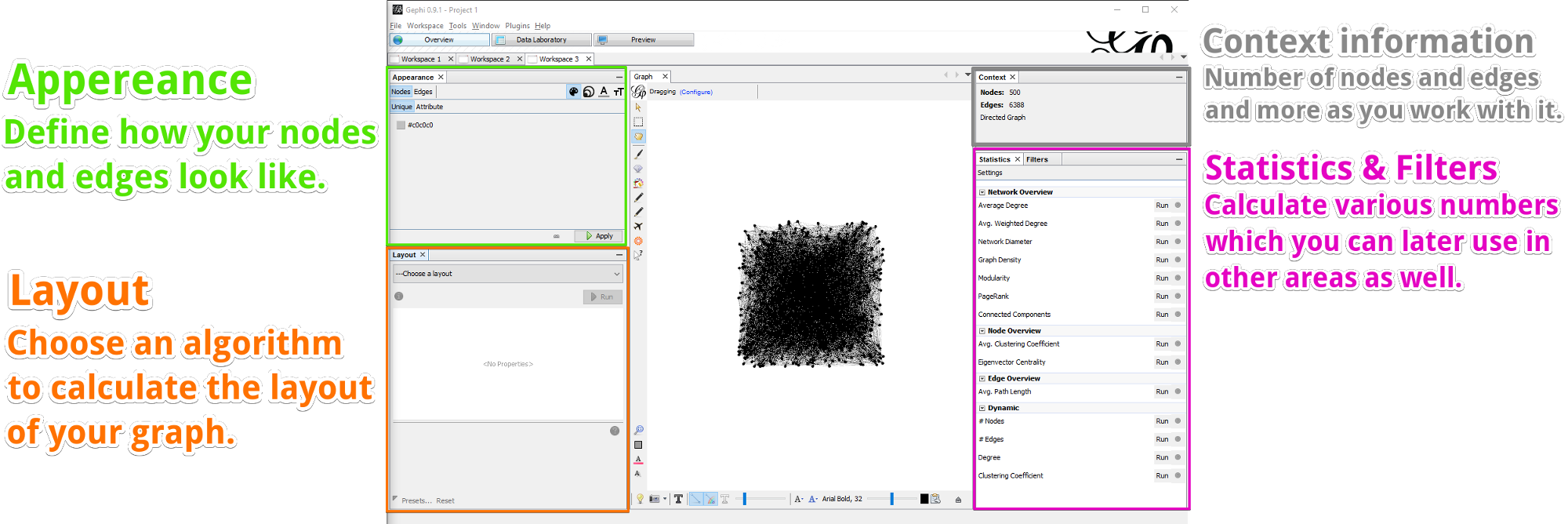
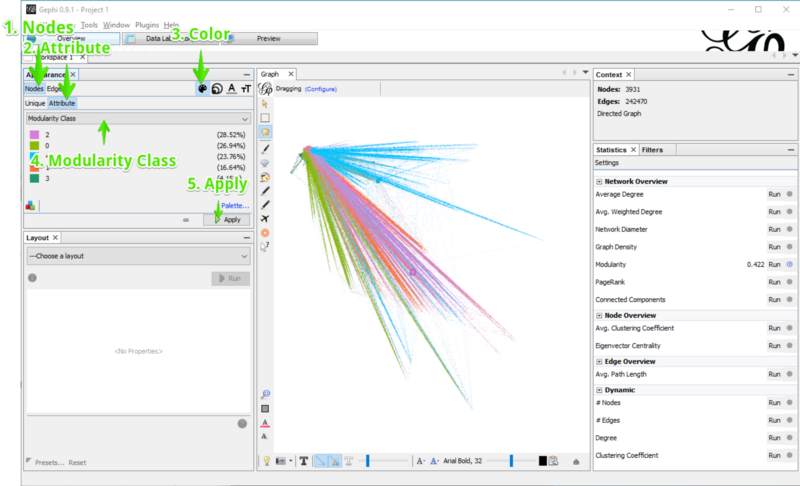
Appearance
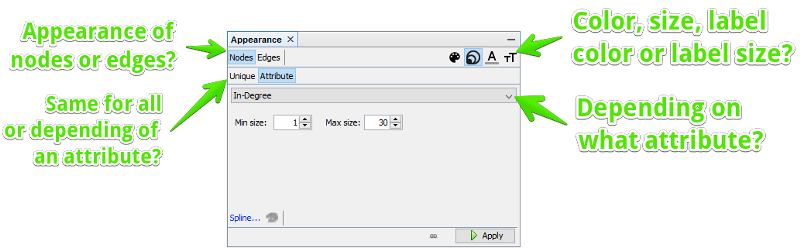
You can change the appearance of nodes and edges. Nodes have a color, size, label color and label size. Edges don’t have a size.
All options can be set as Unique, meaning that every node/edge gets the same look or by Attribute. Depending on what you want to change the attribute needs to have a certain level of measurement. Colors take everything, nominal level. The attributes don’t need to have any relationship with each other. Sizes need to be on an ratio scale. In practice that means, the attribute has to be a number. In theory there should be a meaningful zero value and you need to be able that something is twice as much as something else.
Once you have set the options you want, you need to apply them to the graph by pressing the “Apply” button.
Bonus: Spline can be used to use an attribute in a non-linear fashion. You can for example define that small nodes become bigger faster than big nodes. This is especially useful if you have some extremely big ones.
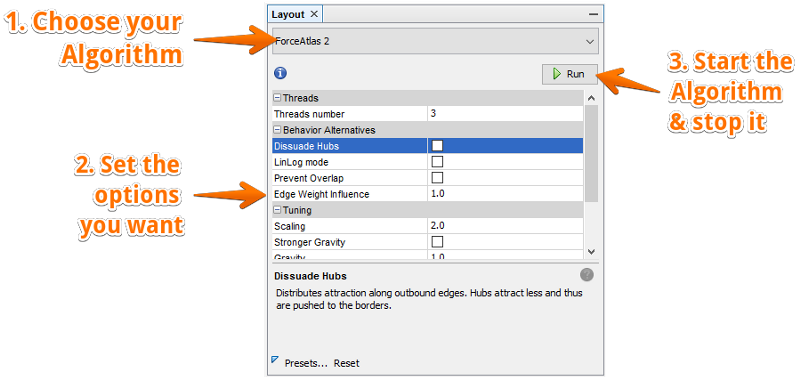
Layout
The layout area gives you access to various algorithms, you can use to calculate the layout of your graph. Each algorithm has it advantages and disadvantages. For social network graphs ForceAtlas 2 or OpenOrd is a good starting point. Some algorithm finish themselves, some need to be stopped once you like the result. Some algorithms can be run after others and only do minimal adjustments (expansion, contraction, noverlap, label adjust) others will completely change how the graph looks like. You can click on each setting of each algorithm to get additional information of what it does.
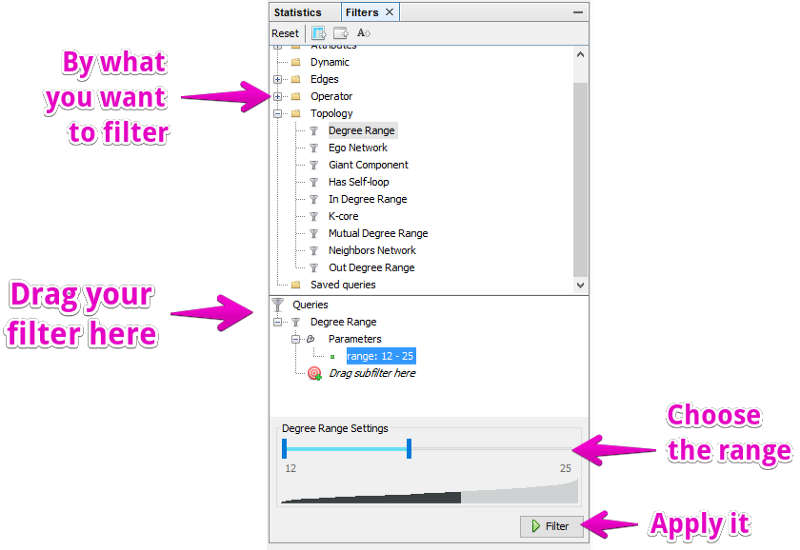
Statistic & Filters
While the statistics options aren’t self explaining, they all work the same. You click on Run and get a results page displayed. As long as you don’t want to write a paper on a graph, you probably only need Modularity, which identifies sub-communities. Once an option ran, you can always access the results page by pressing the little question mark besides the Run button.
Filters are used more often in exploratory settings, because they help you look at only parts of the graph. Again there are many options to choose from, you will most likely work with Attributes and Topology. Queries can be combined.
To apply the filter, click Filter. Click Stop (same button) once you don’t want the filter anymore. While the filter is active, you will get new information in the Context area at the top left, how many nodes and edges are visible.
Graph
In the center of the Overview view is the Graph. You can move around by holding the right mouse button, zoom with your scroll wheel and select/drag/color/??? nodes by clicking left on them. Each of the settings on the side and bottom has a mouse over tooltip. Be careful with the settings at the bottom left. The first one, the magnifying glass is useful, when you get lost, because it centers the view on your graph. The three settings below reset colors and sizes. Irreversible. The buttons and the bottom help you to make the graph more readable or exploreable at all, if it’s to big. Turning of the display of edges helps a lot in such cases.
Data Laboratory
The Data Laboratory gives you the raw data. You can switch between nodes and edges. Through the configuration you can set if you want to see everything or only the things that are visible in the Overview. For example if you activated a certain filter, you probably want to only see the things that fit to the filter. You can export the data or import it and other things. Sometimes you don’t need to do anything here, especially with a nicely prepared data set.
Preview
Once you are happy with your graph, you can use the Preview to render it. There are different presets and many settings to render it as you want it. At the bottom left you have the option to export it as SVG, PDF or PNG. With the Preview ratio, you can set to only render a percentage of the whole graph. This helps a lot if you need to find the right settings for a big graph which takes some minutes to hours to be render completely. In the Preview you move around by holding the left mouse button while moving. Think of it as grabbing the whole image and moving it. You can also zoom in and out. But you can choose nodes or do other things you can do in the Overview.
Network Visualization with Gephi
The following steps don’t necessarily happen in that order. You will go back to certain steps again and again. The layout algorithms are probably the most important tool to make sense of your data. You will try several of them with various settings and come back to them until they fit the need of the current data set.
Open the data set
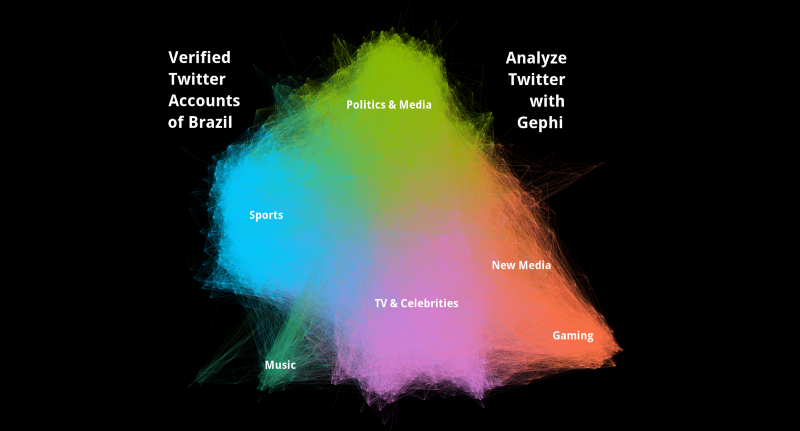
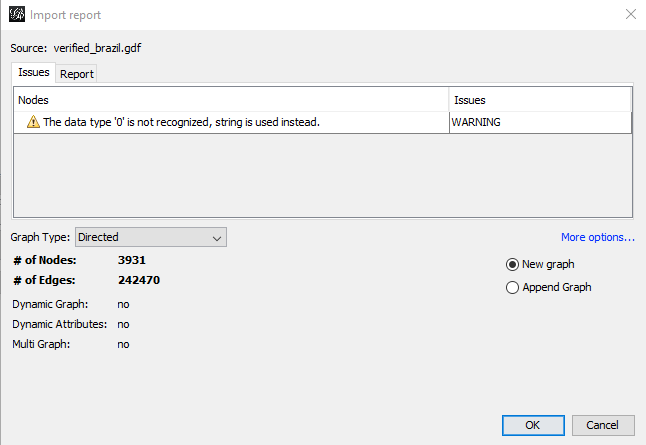
You can click File in the main menu and then Open or double click the file or Ctrl+o or use the Welcome Dialog. Gephi will then present some information about the Graph and may display warnings and errors. In my example, the Brazilian sub-community of verified Twitter accounts, I get a warning about a falsely defined data type. Looking in the Data Laboratory I can see that edges have one column too much but there aren’t any other problems with the data. Therefore I ignore the warning for now.
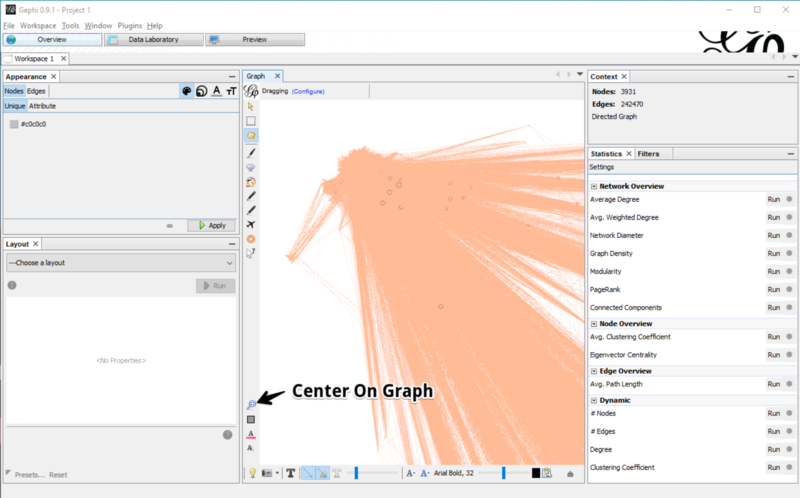
Center on Graph
After the graph is loaded, I don’t see much. All nodes have the same color and I don’t see the whole graph. I could zoom out with the mouse and try to get see the whole graph, but I decide to use the quicker way of clicking the center on graph button in the center bottom left.
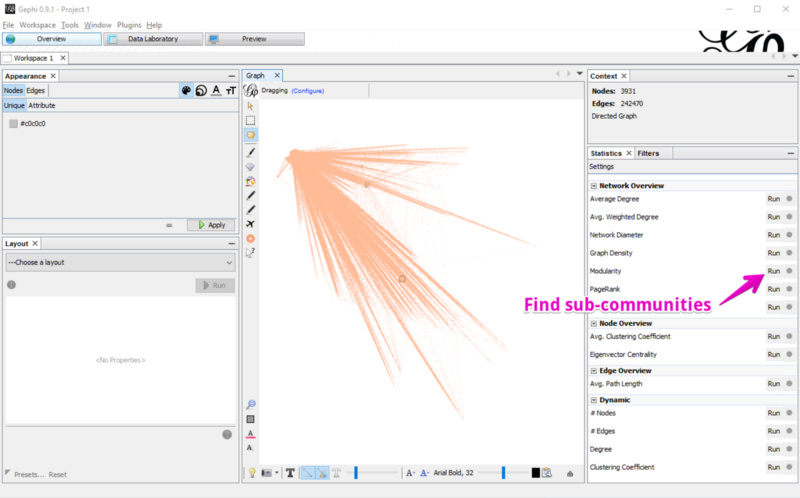
Find sub-communities by calculating Modularity
Now we can see the whole graph. But it’s still quite chaotic. Let’s see if we can find some sub-communities. I click Run in the right Statistics section at Modularity.
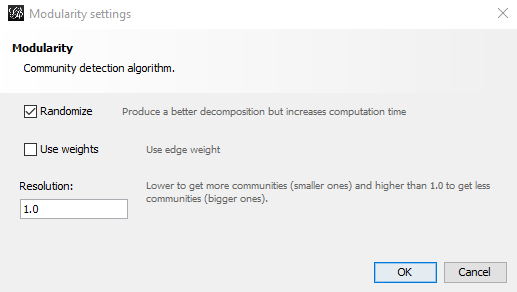
Because I know the edges don’t have weights, I turn off the option that edge weights plays a role for the calculation.
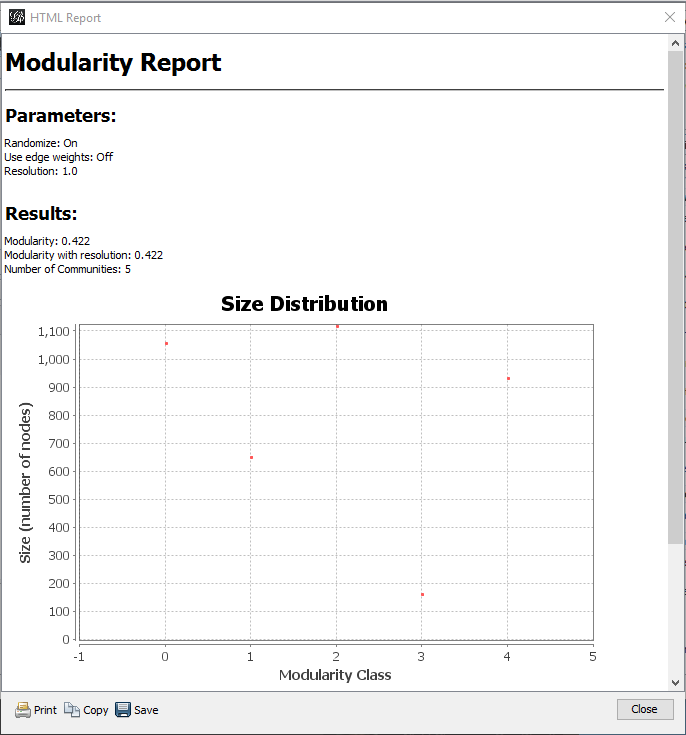
We get a report that 5 communities were found.
Color nodes by community
Let’s use the communities to color the nodes. This will help us see the communities easily. The setting is on the left in the Appearance section. We want to change the color of nodes by modularity attribute.
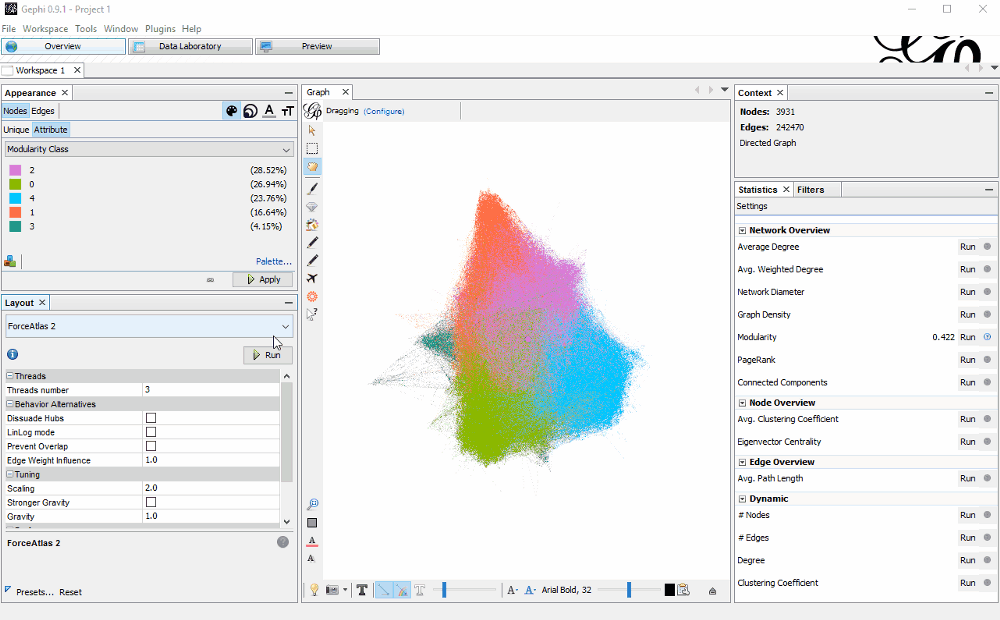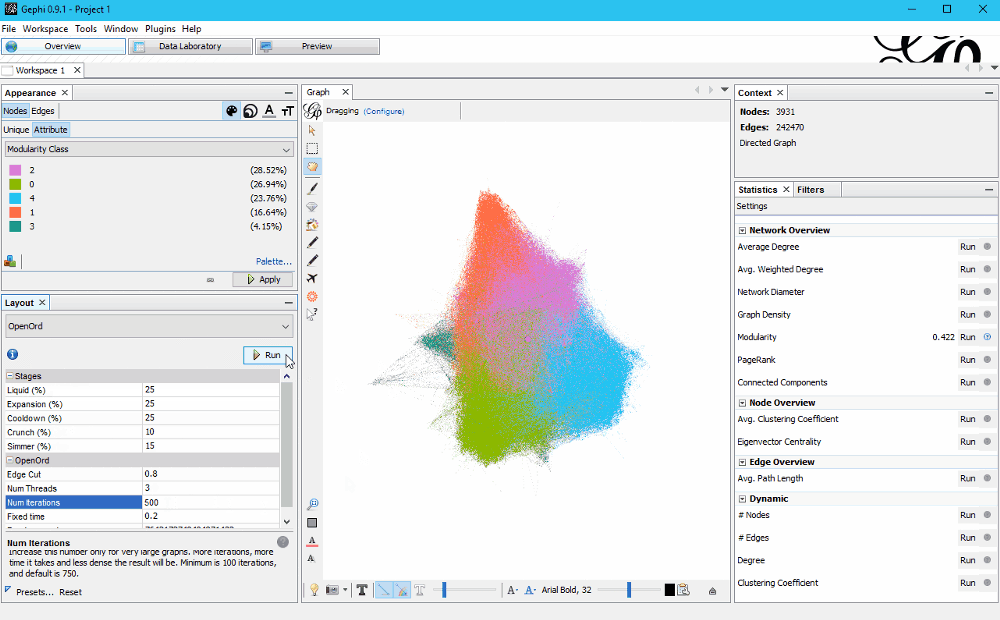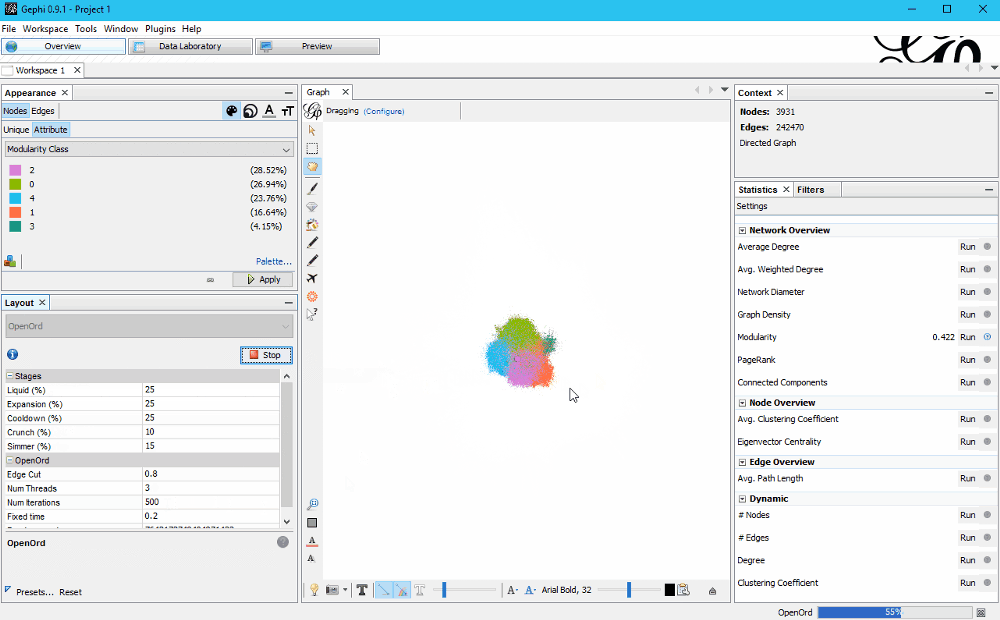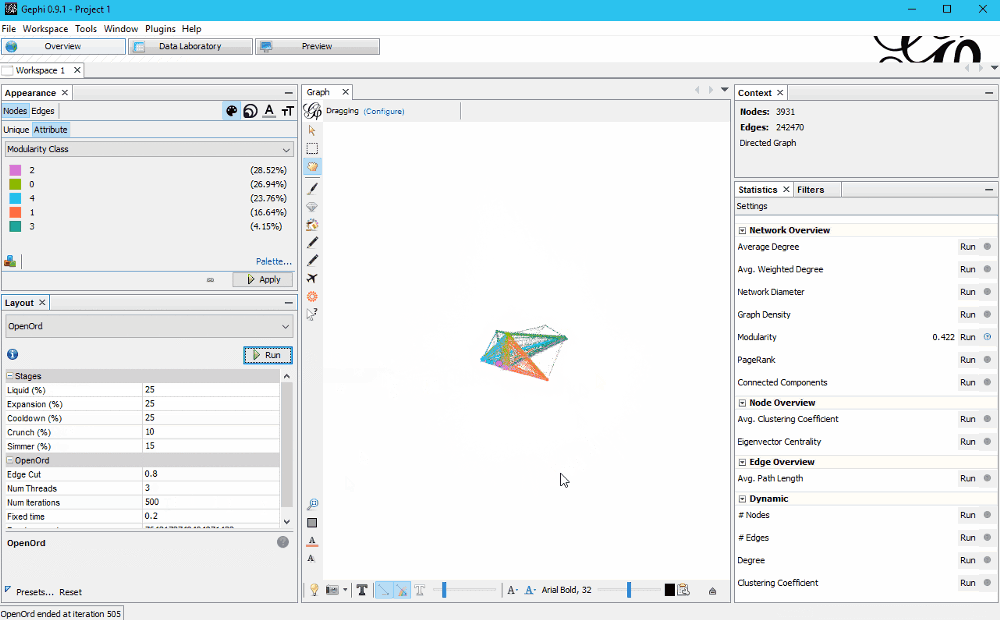
Layout Algorithm
I like to start with ForceAtlas 2. In many cases it gives a good result. Once there isn’t much movement going on anymore, I stop it. While it’s calculating the graph moved outside of my view and I centered it again.

Because I liked the result of OpenOrd a lot on the big graph, I try it again with the small one but aren’t as happy with the result.
I liked the ForceAtlas 2 layout better, so I run it again. This time with Scaling 5.
Set node size by in-degree
I want to know who are the most important nodes in this specifc data set. Therefore I go to Appearance -> Nodes -> Size -> Attribute -> In-Degree and limit the size from 1 to 100 after testing around which size works best for this graph. After that I turn on labels and set their size to node size. Or you could do this permanently by setting the label size in the Appearance settings.
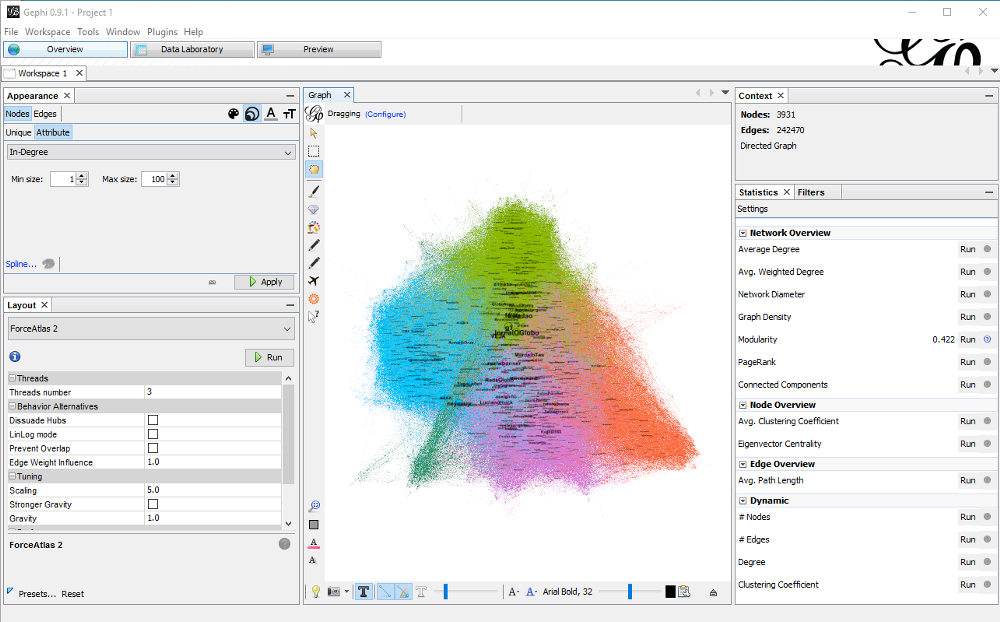
Explore the Graph
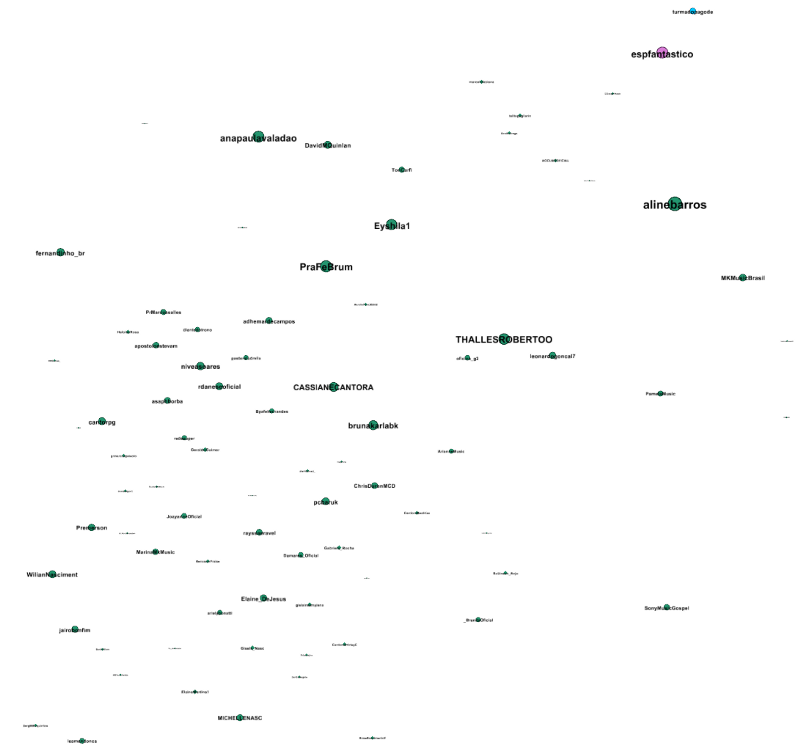
Now is a good time to get a better feeling for the graph. That means a lot of zooming, scrolling, reading labels and looking up more information of the nodes. In the case of Twitter accounts, I look at their accounts in a browser. If moving around is too slow, I turn off edges (bottom of the screen besides the big T). If my screen is too small, I minimize everything but the graph by clicking on the minus of each section.

The blue community looks seems to be about sport.

The green one seems to be politics and media. I don’t know a lot about these things in Brazil and am thankful that someone contacted me to help me out with it. You get much more out of a visualization if you don’t have to look up everything and can interpret them.

The purple ones appear to me as TV/Lifestyle/Celebrities.
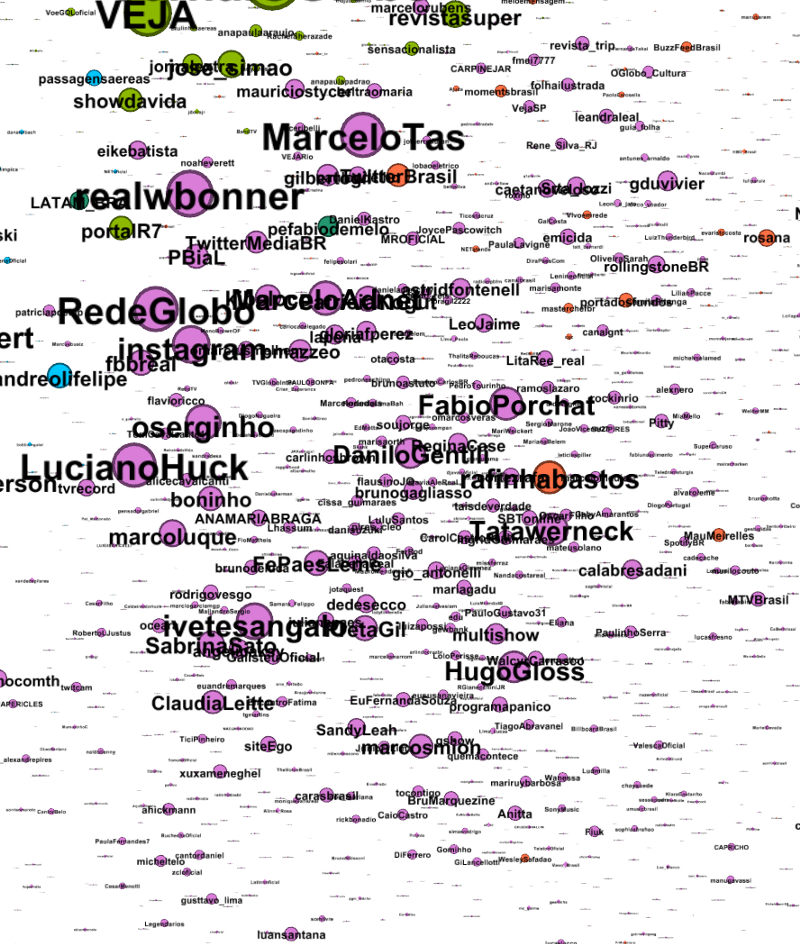
Red could be new media and gaming.
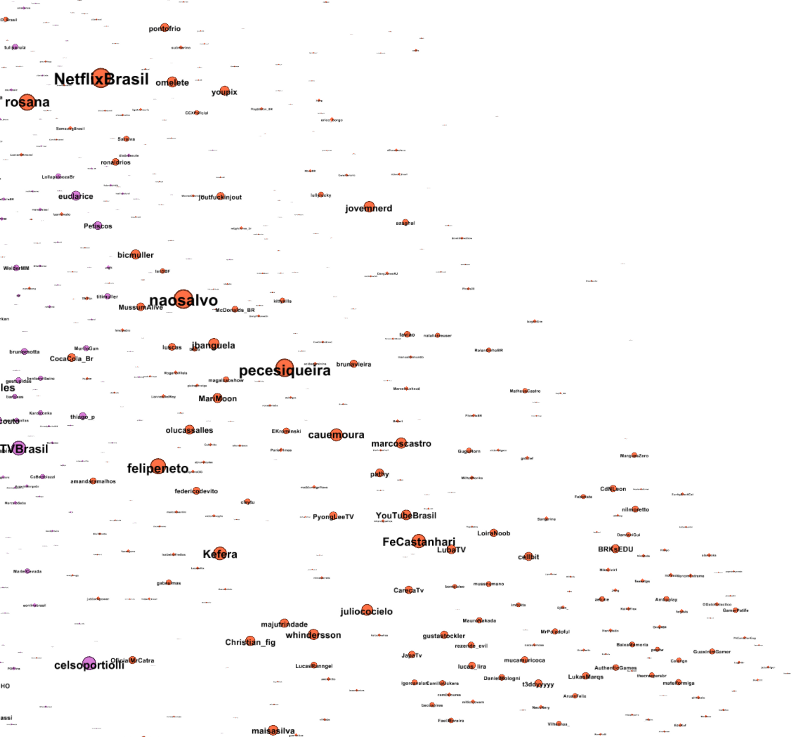
Bottom left sounds like music.
Render it
When I think everything looks good and I am ready to share what I found, I go to the Preview and play around with different rendering settings. After exporting or screenshooting the render I enjoy the most, I sometimes put the labels I found for the sub-communties on them. Sometimes I share it as it is and add the explanation as text.

Troubleshooting
Out of memory
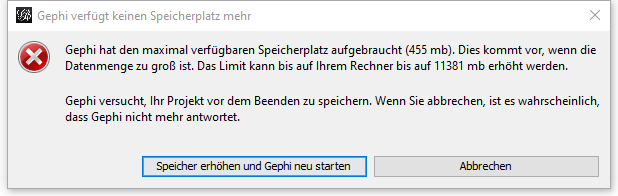
The automatic memory increasing never worked to me. You could still give it a try. If it doesn’t work, I will show you how to edit it in the Gephi Config.
First you need to locate the Gephi Config file. Depending on where you installed Gephi, you should it in the /etc folder. For me the path is
C:Program Files (x86)Gephi-0.9.1etc
Open the file with a text editor of your choice. Atom is a popular choice.
The relevant parameter is -J-Xmx512m. It defines how much memory Gephi is allowed to use. 512m would be 512 Megabyte of RAM. In the past it was important that the allowed RAM doesn’t exceed the available RAM. I don’t know how and when it changes, but at the moment it seems that you can allow it as much RAM as you want. Maybe this is only possible on Windows 10 with an SSD because it gets treated as slower RAM. Remember the “expand RAM with USB stick”? On my computer with 16GB RAM I set it to 64000m or something around 64GB. I always make sure there is enough free space on the SSD if the additional RAM is really needed. Windows puts things from the RAM into the page file, the virtual RAM on the SSD/HDD, when a program requests more RAM. Compared to the RAM the SSD is very slow. But sometimes it’s the only way to open a certain graph.
# ${HOME} will be replaced by user home directory according to platform
default_userdir=”${HOME}/.${APPNAME}/0.9.1/dev”
default_mac_userdir=”${HOME}/Library/Application Support/${APPNAME}/0.9.1/dev”
# options used by the launcher by default, can be overridden by explicit
# command line switches
default_options=” — branding gephi -J-Xms64m -J-Xmx64000m -J-Xverify:none -J-Dsun.java2d.noddraw=true -J-Dsun.awt.noerasebackground=true -J-Dnetbeans.indexing.noFileRefresh=true -J-Dplugin.manager.check.interval=EVERY_DAY”
# for development purposes you may wish to append: -J-Dnetbeans.logger.console=true -J-ea
# default location of JDK/JRE, can be overridden by using — jdkhome <dir> switch
#jdkhome=”/path/to/jdk”
# clusters’ paths separated by path.separator (semicolon on Windows, colon on Unices)
#extra_clusters=
I will add further problems and solutions, as you ask for them.
Further resources
The Gephi Facebook Group is a great location to ask various questions.
https://www.facebook.com/groups/gephi/
Leave a Reply