On 06.02.2019 OpenCorporates in cooperation with Open Knowledge Foundation Deutschland published data of 5.3 million Germany companies that are registered with Handelsregister. This data should be publicly available for free, but isn’t currently. You can read how they collected the data and download it from offeneregister.de.
I did a quick exploration of the data on Twitter. In this article I explain how I worked with the data and share the Python code I used. You may use the code anyway you want. Attribution would be nice, but isn’t necessary.
This article targets people with a basic understanding of Python. If you have more experience than me, feel free to point out mistakes or improvements in the comments.
tl;dr;
- Put script in project directory
- Put jsonl it in /local_data/ within project directory
- Run offene_register.py
- Open resulting .gdf in /local_data/ with Gephi
- Adapt offene_register.py
- Go to 3.
About the data
It’s available as a SQLite database or jsonl. I choose the jsonl-file. Use the torrent download for more speed and saving bandwith. The compressed file measures 255MB, uncompressed it’s just over 4GB. My code goes through the data line by line, so it works even with few RAM. If you want to load the whole dataset into Python for much faster analysis, it will use about 25GB of RAM.
I decompressed the jsonl and put it in a subdirectory (/local_data/) below the directory of my script.
Understanding the data
First, I need to understand the data. What data is available about each company, how is it structured and so on.
jsonl is a file with one json-object per line.
Per default get_companies() returns the first company in the jsonl. It doesn’t matter to me which company it is. I just want to have a first look at the data. By adding parameters I can change how many companies it returns and at what line it starts. get_companies(500, 3) would return the companies on line 500, 501 and 502. I am using prettyprint to make the output more readable.
import json_lines
import pprint
pp = pprint.PrettyPrinter(indent=1)
def get_companies(line_number=0,lines=1):
"""
Returns as many companies as you want as a list.
The higher the starting line, the longer it takes.
"""
companies = []
with open('local_data/de_companies_ocdata.jsonl', 'rb') as f:
current_line = 0
max_line = line_number + lines
for company in json_lines.reader(f):
if current_line >= max_line:
return(companies)
if current_line >= line_number:
companies.append(company)
current_line += 1
pp.pprint(get_companies(0,2))| company_number | A unique identifier for the company following the EUID approach. | |
| current_status | ‘currently registered’ (2 393 517) or ‘removed’ (2 912 209) | |
| jurisdiction_code | Always ‘de’ in this dataset. Useful when you combine it with other datasets. | |
| name | Name of the company. | |
| previous_names | Names the company had in the past. Available for 1 020 993 companies. | |
| officers | Officers of the company. Can be persons or organizations. Can have additional attributes. Available for 2 006 145 companies. | name type position start_date end_date other_attributes |
| registered_address | Street address of the company. Data in this field felt most inconsistent. Probably because of how companies enter it and how it was scraped. Sometimes contains data from other fields. Available for 1 670 706 companies. | |
| retrieved_at | When the data was collected. | |
| all_attributes | More attributes that may exist. | _registerArt _registerNummer additional_data federal_state native_company_number registered_office registrar |
There is a sample data entry on the bottom of the readme as well.
Creating network files
I am using Gephi for network analysis. Normally I tend to use GEXF, but because it is based on XML, it has some overhead. In this case I choose GDF. It’s similar to CSV and produces probably the smallest filesize. But it’s more error prone when items contain commas or new lines.
There are at least three network graphs we can create.
- Companies connected by officers (undirected)
- Officers connected by companies (undirected)
- Officers and companies connected with each other (directed)
Loading data
To not have to go through the whole 4GB file every time, I created a data object containing two dictionaries. One with every officer (name and their companies) and one of every company (name and company number).
def get_companies_and_officers():
'''
Returns lists of all currently registered
companies and their officers.
'''
data = {'allofficers': {}, #[{name: ['company 1', 'company 2']}]
'allcompanies': {}}
with open('local_data/de_companies_ocdata.jsonl', 'rb') as f:
for company in json_lines.reader(f):
if 'current_status' in company:
if company['current_status'] == 'currently registered':
data['allcompanies'][company['company_number']] = company['name']
if 'officers' in company:
for officer in company['officers']:
if officer['name'] in data['allofficers']:
data['allofficers'][officer['name']].append(company['company_number'])
else:
data['allofficers'][officer['name']] = [company['company_number']]
return(data)
data = get_companies_and_officers()Only companies with the stats ‘currently registered’ and currently active officers will be in data to further reduce the size of the network. Let’s quickly look at the numbers.
len(data['allcompanies'])
len(data['allofficers'])
There are 2 393 517 currently registered companies with 1 341 555 active officers.
Companies network
The script first goes through the list of companies to create the nodes. Company number as ID and name as label. Commas and new lines are replaced. Then it goes through the officers and creates an edge between each company an officer is connected with.
def create_companies_network(data):
'''
Writes a .gdf with companies
connected by officers.
'''
with open('local_data/offeneregister-companies.gdf', 'w', encoding='utf-8') as output:
output.write('nodedef>name VARCHAR,label VARCHAR\n')
for company,name in data['allcompanies'].items():
output.write('{0},{1}\n'.format(company,name.replace(',','COMMA').replace('\n', 'NEWLINE')))
output.write('edgedef>node1 VARCHAR,node2 VARCHAR\n')
for officer,companies in data['allofficers'].items():
for i, company in enumerate(companies):
for y in range(i+1, len(companies)):
if companies[i] != companies[y]:
output.write('{0},{1}\n'.format(companies[i],companies[y]))
print('Companies network created.')
create_companies_network(data)The resulting GDF is about 480MB.


688 420 currently registered German companies, connected through 8 668 853 currently active common officers connections. 1k iterations of ForceAtlas2. Removed companies without connections.
Officers network
Officers are already in the structure we need. Therefore I don’t need to load the data first. Because officers don’t have a unique identifier, I don’t need to create nodes with labels but can let Gephi handle it.
def create_officers_network():
'''
Writes a .gdf with officers
connected by their companies.
'''
with open('local_data/de_companies_ocdata.jsonl', 'rb') as f:
with open('local_data/offeneregister-officers.gdf', 'w', encoding='utf-8') as output:
output.write('nodedef>name VARCHAR,label VARCHAR\n')
output.write('edgedef>node1 VARCHAR,node2 VARCHAR\n')
for company in json_lines.reader(f):
if 'current_status' in company:
if company['current_status'] == 'currently registered':
if 'officers' in company:
for officer_a in company['officers']:
if 'end_date' not in officer_a:
for officer_b in company['officers']:
if 'end_date' not in officer_b:
if officer_a['name'] != officer_b['name']:
output.write('{0},{1}\n'.format(
officer_a['name'].replace(',', 'COMMA'),
officer_b['name'].replace(',', 'NEWLINE')))
print('Officers network created.')
create_officers_network()The resulting GDF is about 220MB.
Officers and companies network
A full network of all officers and companies would be too big for my computer. Therefore I choose to filter by registrar. The resulting networks are easier to handle. But we miss cross-registrar networks.
def create_officers_companies_network(registrar='München'):
'''
Writes a .gdf with companies and
officers connected by each other.
'''
nodes = []
edges = []
with open('local_data/de_companies_ocdata.jsonl', 'rb') as f:
for company in json_lines.reader(f):
if company['all_attributes']['registrar'] == registrar:
if 'current_status' in company:
if company['current_status'] == 'currently registered':
nodes.append('{0},{1}\n'.format(
company['company_number'],
company['name'].replace(',', 'COMMA').replace('\n', 'NEWLINE')))
if 'officers' in company:
for officer in company['officers']:
if 'end_date' not in officer:
edges.append('{0},{1},TRUE\n'.format(
officer['name'].replace(',', 'COMMA').replace('\n', 'NEWLINE'),
company['company_number']))
with open('local_data/offeneregister-combined-{0}.gdf'.format(registrar), 'w', encoding='utf-8') as output:
output.write('nodedef>name VARCHAR,label VARCHAR\n')
for node in nodes:
output.write(node)
output.write('edgedef>node1 VARCHAR,node2 VARCHAR,directed BOOLEAN\n')
for edge in edges:
output.write(edge)
print('Combined network created.')
create_officers_companies_network('Köln')Files vary in size but most of them are smaller than 10MB.
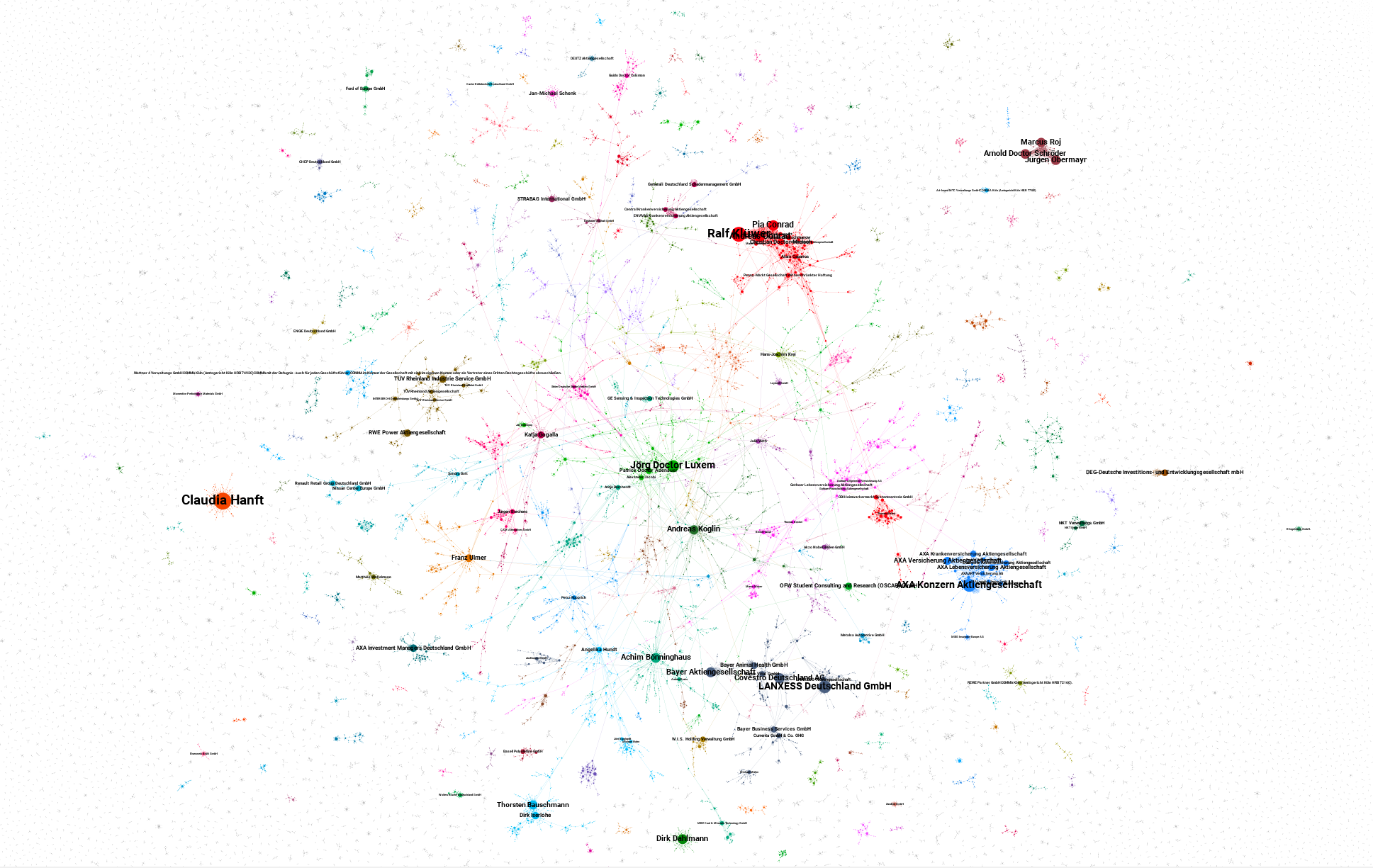
Problems and ideas
Officers names aren’t unique, but the script treats them as such. It would be possible to combine the names with other data in the dataset but it’s likely that that data is not consistent as the addresses already proved.
The full networks are slow on my computer. I will probably experiment with filtering them.
I already saw some interesting patterns. There are clusters with obvious themes (real estate, investment, retirement homes,…) and other ones I don’t understand yet. Time is my biggest constraint. You can hire me to look at the data with you. If you are a NGO or student, feel free to contact me without a budget as well.
Bonus
A great interactive tool was made by Johannes Filter:
https://vis.one/netzwerk-deutscher-unternehmen/