After my computer upgrade from a 4 cores, 4 threads CPU with 32GB RAM to a 12 cores, 24 threads CPU with 64GB of RAM how this changes my daily number crunching work as a Social Media Analyst.
I am not a professional hardware reviewer. I only want to get a feeling if and how much faster the new build is for my workloads. I already know that the single core performance would be similar and I need to change how I write code in the future to take advantage of the high core and thread count.
I tested the old build with Windows 10 and the new build with Windows 10 and with Ubuntu 18.04 because Linux seems to be better at utilizing more cores.
Gephi Performance
Let’s start with the main reason for the upgrade. Gephi. It’s a wonderful tool for network analysis. I use it quite often and wrote multiple articles about it. While it’s quite efficient, the bigger a network is, the more RAM it needs. If a network is too big, you have to choose which parts you want to analyze and reduce it accordingly. To not run into this problem that often, I upgraded to 64GB of RAM. Some of the calculations in Gephi can use multiple cores, while others are single-threaded.
For this test, I used a Twitter Follow-Network (127k nodes, 31M edges) from a recent project. This gives me results that are close to reality, but at the same time not standardized and hard to compare. But there are already enough synthetic benchmarks out there. I am more interested in real world performance.

GDFs are easy to create and have a small footprint. They are like two CSVs merged into one. First part nodes, second part edges. The test file has nearly 32 million lines. Surprisingly the seven year old 4670k with a slower SSD and slower RAM was nearly 30% faster than the Ryzen 3900X.
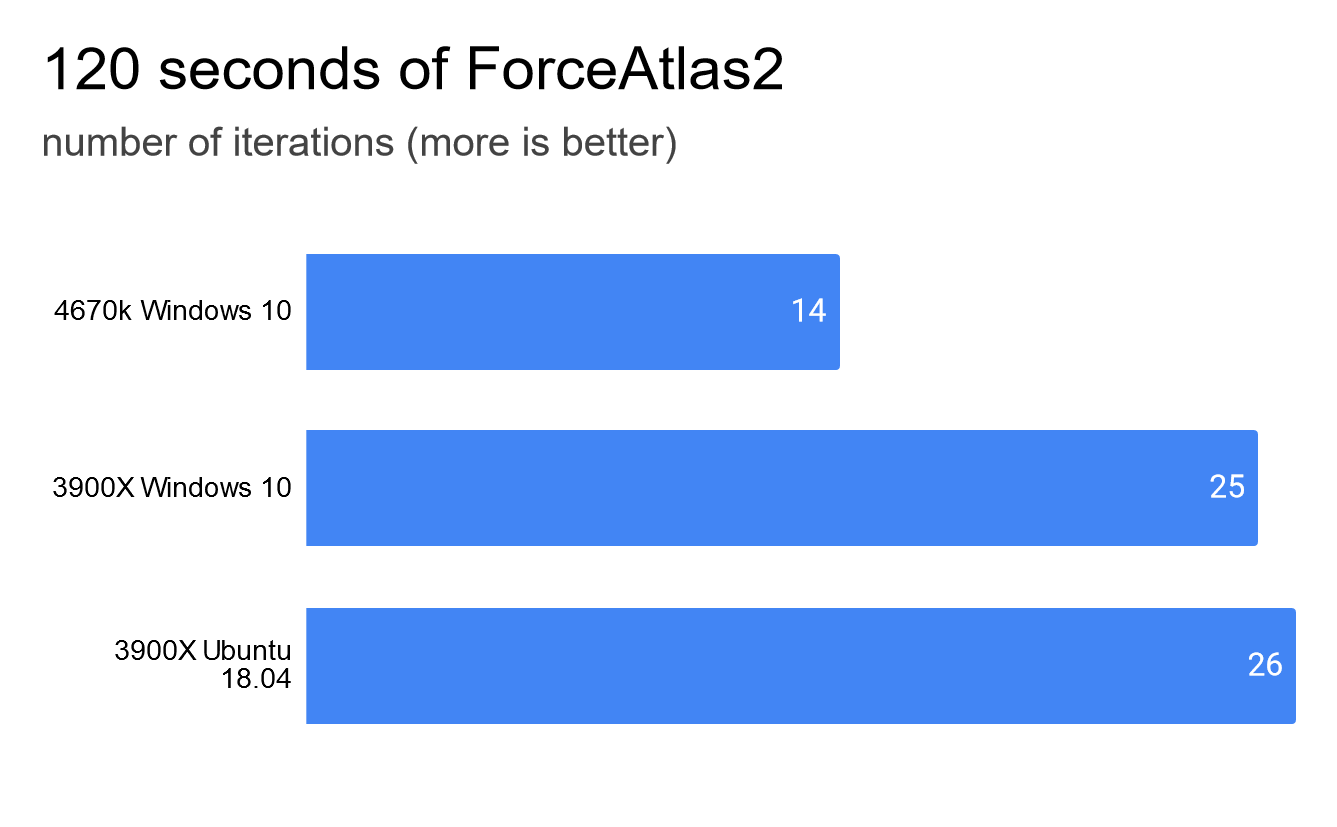
ForceAtlas2 is a layout algorithm which calculates the position of nodes in a network. It is optimized for multiple cores. As a result the 3900X was able to do nearly two times as many iterations as the 4670k.
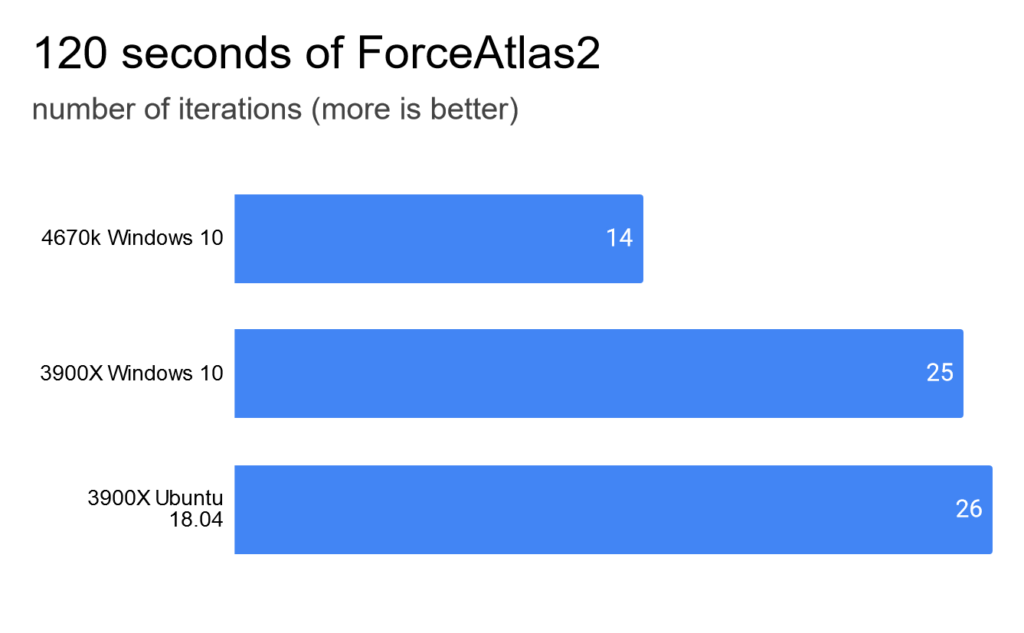
The Leiden algorithm calculates clusters in a network. It’s a quite new algorithm and apparently not optimized for multiple cores. The old build was 12% faster than the new one.

The Modularity algorithm calculates how modular a network is and as a side product clusters in the network. The old build needed nearly two times as long because it ran out of RAM and had to write and read a lot from the page file on the SSD.

When rendering a preview of the whole network with all 31 million edges, the old build took over half an hour, while the new one finished in about ten minutes. Again, the old one ran out of RAM.

Gephi uses a binary file format to store projects. The old build was slightly faster than the new one. But only on Windows 10. On Ubuntu the new build was the faster.

GEXF is another file format to store networks. It’s based on XML and has quite some overhead. Once again, the old build was faster than the new one. Though there is quite a difference between Windows 10 and Ubuntu.
Conclusion of Gephi performance tests
Surprisingly the old Intel 4 threads processor was able to beat the new AMD 24 threads processor in some tests. It’s faster when working with text files, which resulted in faster load times of GDF and GEXF files. It was faster when calculating Leiden clusters as well. While Ubuntu and Windows 10 showed a very similar performance, Ubuntu was slightly faster with text files as well. It really shined when loading a binary file.
For calculating the layout and rendering the network, the new build was vastly faster.

When adding the times of all operations, the new build is about twenty minutes faster than the old one. Though, normally you would let the layout algorithm run longer and not open the same file three times. Though opening the .gephi file more than ones happens often. Even using .gexf in between as a backup, because .gephi sometimes becomes corrupt is a realistic scenario.
Pandas and Dask Performance
When working directly with the data, I love to use pandas. I created an example Jupyter notebook with some operations, I would normally do as well. You can look at the notebooks yourself: 4670k, 3900X Windows 10, 3900X Ubuntu 14.04.
For theses tests I used a real dataset from a recent project as well. Half a million Tweet objects in a jsonl-file.

First I need to load the Tweets into a dataframe. This time the 4670k was last. Though not by far. About 10% slower. But Ubuntu was nearly another 10% faster than Windows 10.

I didn’t work with Dask in the past, but read great things about it. It scales from a local cluster (to fully utilize all cores) to globally distributed clusters. I still have to figure out how to use it optimally, but so far I like it. To use it, you have to create a Dask dataframe, which is fastest on Ubuntu.

Executing a function on all rows of the dataframe was faster on Windows than on Ubuntu, but only slightly.

I assumed that Dask would be faster when executing the same function on all rows, but on Windows it was about a second slower. I assume that pandas is already so optimized that dask only makes sense for more expensive functions. Ubuntu was weirdly slow.

Using dask with processes instead of threads was even slower. Especially Ubuntu was off. It ran out of RAM and had to use the swap file.

Thinking I did something wrong with dask apply, I tried map_partitions. I used 5 partitions in the test. The result was nearly the same as with apply.

Same test with processes instead of threads. Again Ubuntu ran out of RAM. No overall improvement.
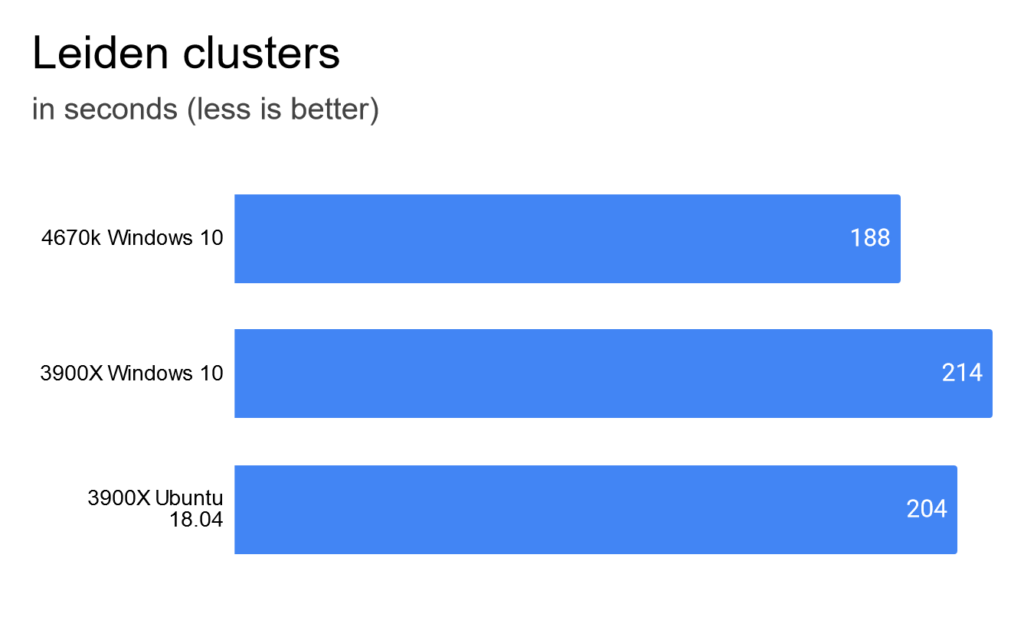
Let’s try something different. I use groupby often and it’s very fast on the old and new build. Ubuntu is a bit slower, but because it only takes about a second in total, the difference is not relevant.

Same operation with dask is even faster. But not enough to off-set the lengthy conversion from a pandas dataframe into a dask dataframe. Depending on how often one uses it.
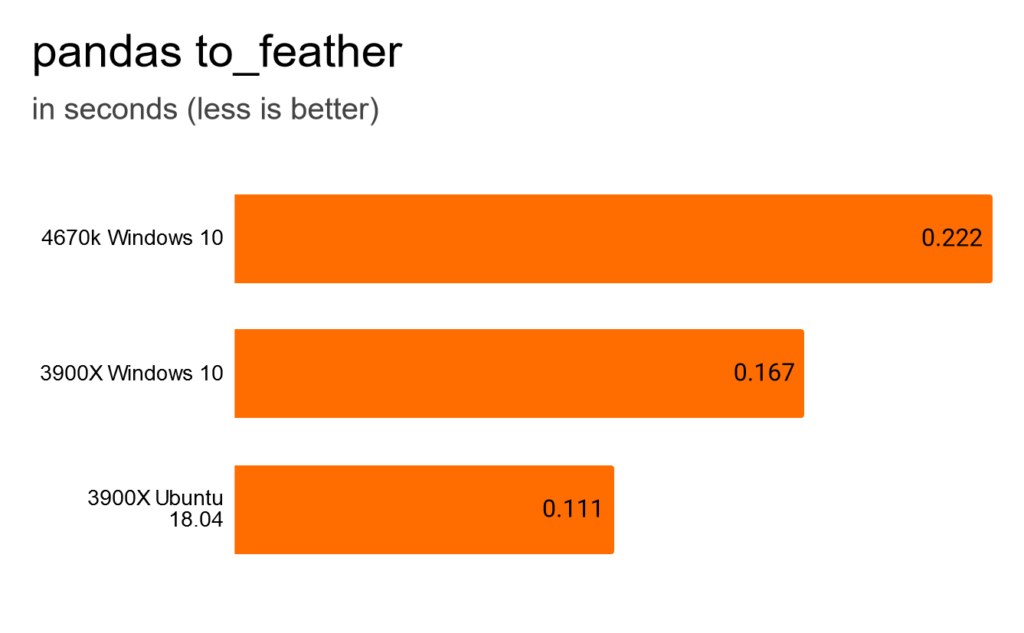
Feather is a binary file format to store data like dataframes. All three setups were blazing fast, but Ubuntu took the crown. Half the time of 4670k. Again, it’s so fast, that the difference isn’t that relevant.
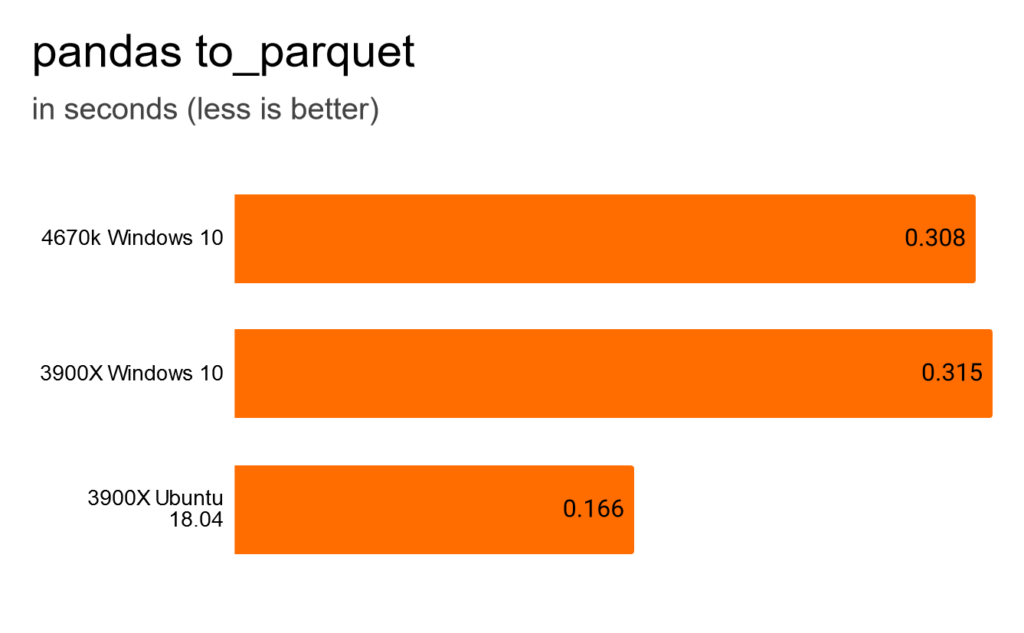
Parquet is another binary file format. Slightly slower than Feather. Ubuntu fastest and Windows 10 with the new CPU slowest.

Reading feather is incredible fast as well. Ubuntu is again nearly twice as fast as the old 4670k with Windows.
Conclusion of pandas performance tests
When using pandas, the new build is nearly always faster. Only writing to parquet was faster on the old one. But Ubuntu on the new one was even faster. But Ubuntu had severe issues with RAM when using dask. I will have to test some more things to find out how to fix that. Overall pandas seems to be more optimized on Windows.
Python Multiprocessing
After failing to create an example that benefits from the multiprocessing capabilities of dask, I tried some plain Python multiprocessing. Here is the script that I used.
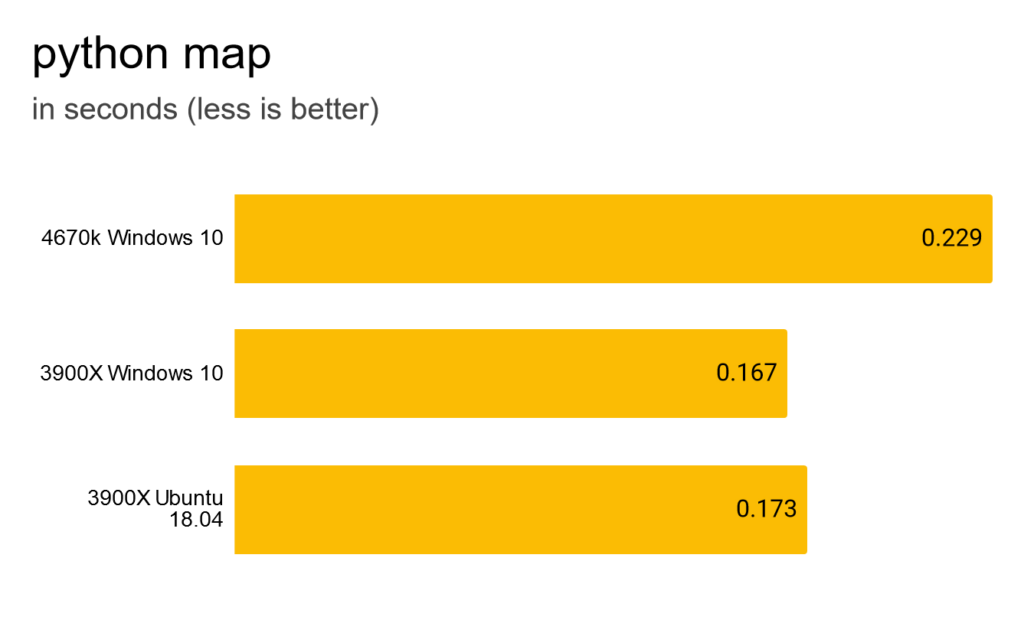
After reading the half million Tweets into one big Python list, I mapped the function to it. What took pandas half a minute, is finished by Python in less than 200 milliseconds. Nice performance difference between the 4670k and 3900X of over 30%.

List comprehensions are the pythonic way they said. So I tried it as well. About the same speed.
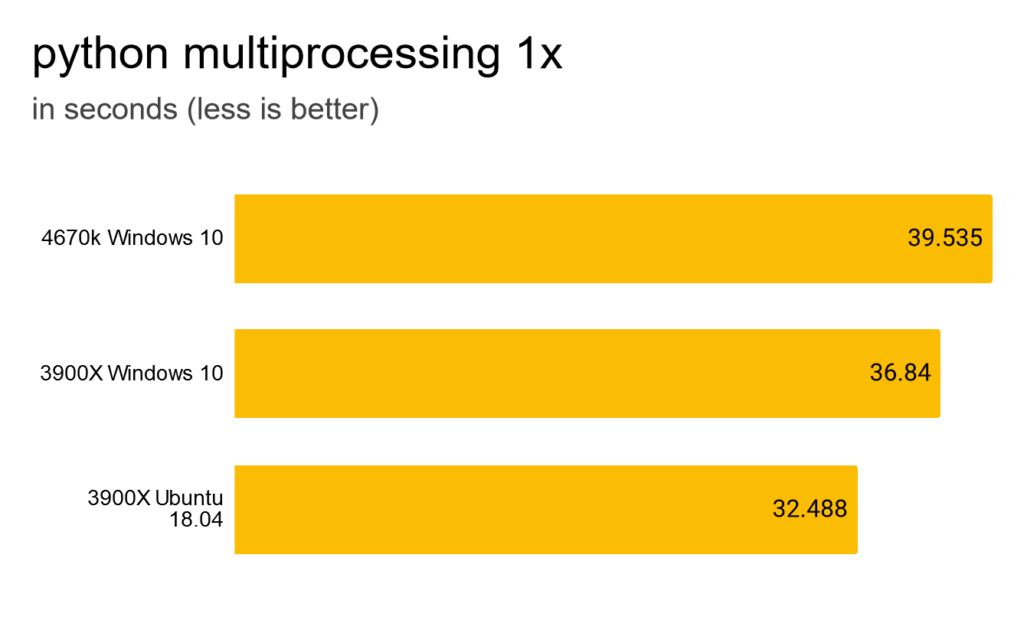
Let’s try the same with multiprocessing. Running in one thread is rather pointless, because it’s all the overhead without any of the benefits. But I wanted to have it as some kind of baseline.
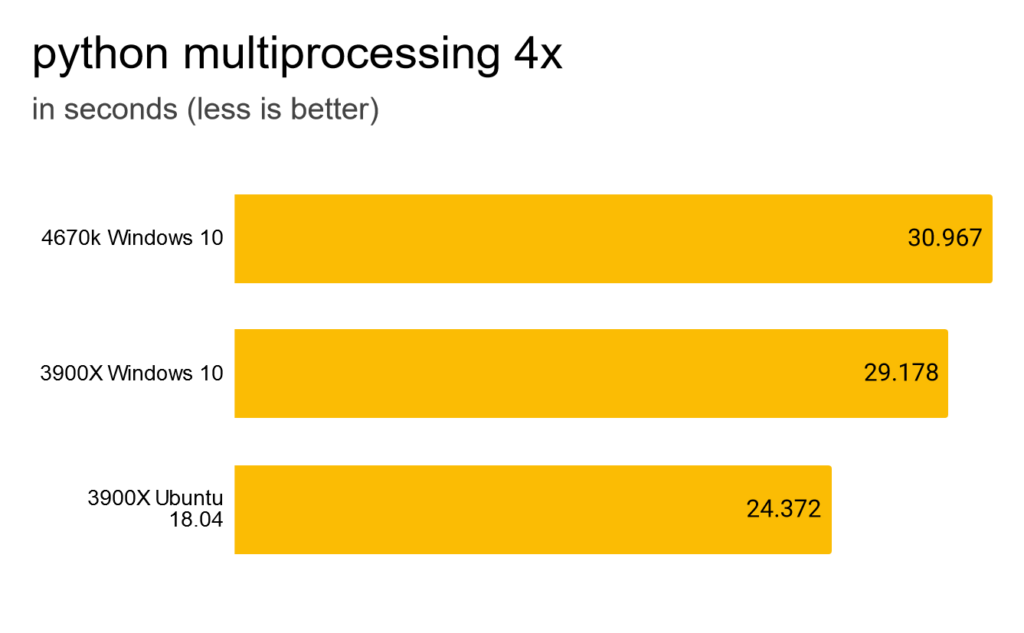
4 processes is faster, but compared to a simple map still incredible slow.
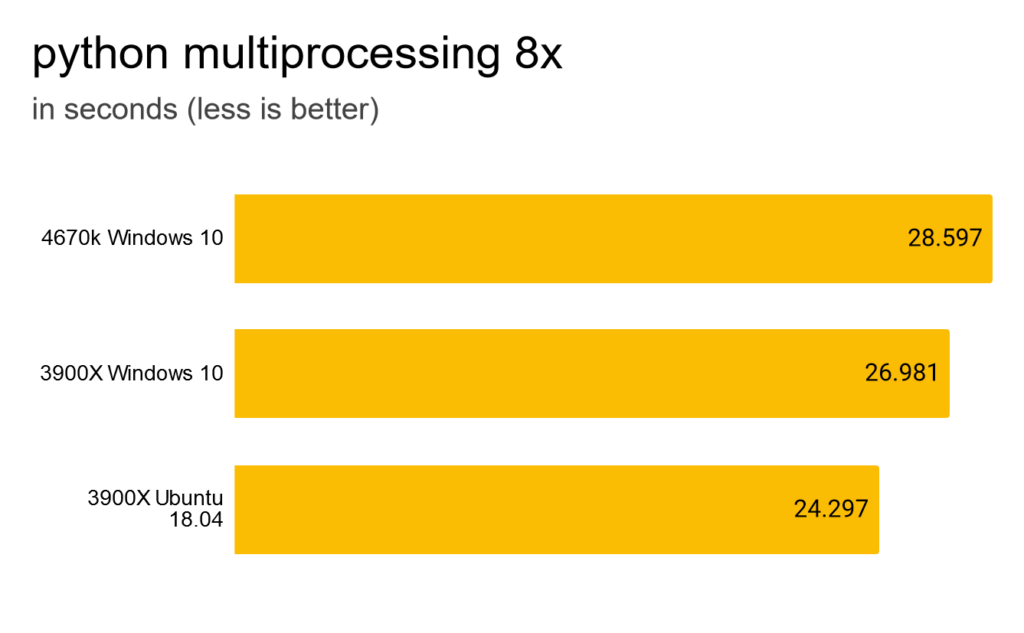
Eight processes is slightly faster.

Twelve processes is faster again, but the difference is small. Ubuntu started to run into RAM issues. Once again.

While I tried 24x, 48x, 96x and 168x, I choose to only show 120x, as they all were quite similar. I surprised me that the 4 thread processor was faster with 120 processes than with 12. Somehow multi processing on Windows has little overhead. But little benefit as well. At least for functions that are way too fast like the one I used.
Conclusion of python multiprocessing performance tests
That was not what I expected. In hindsight the example function I used was the worst I could have tried. While it seems obvious in the article that I should have chosen a more expensive function because map and list comprehension are that fast, when doing the tests, I did them last. I will have to re-test multiprocessing some day.
Leave a Reply