The Twitter Standard API is limited to Tweets from the last 7-10 days. This isn’t enough for most research projects. Since 2018 Twitter offers a Premium API through which the full Twitter archive is accessible. I used it for several projects and am working on implementing it in my Twitter analysis tool to make it easier for students and researchers to collect and analyze old Tweets. Until then and as an alternative, I will show you how to use the Twitter Premium API with Python.
0 Understanding the Twitter Premium API
The Premium API is a subscription service. While the Standard API is free and primarily limited by how many requests you can make within a time frame, the Premium API is mostly limited by how much you can pay.
The subscriptions are tiered. You pay a fixed sum per month and can use a fixed amount of requests. You can upgrade to a higher tier during the subscription period to unlock more requests. With this model you can’t overspend, can’t pay only what you need either.
Currently there are two Premium Search APIs available: 30-days and Full Archive. The only differences are pricing and how far back they go. Both have a free sandbox tier with some additional limits, that let you experiment. But you should be aware that the free requests you use, are counted towards your first paid tier, if you choose to upgrade. I didn’t know that the first time. If you use 50 of the 250 free requests and upgrade to the first tier of 500 paid requests, you will only be able to make 450 requests. Because the free requests are limited to 100 Tweets, while the paid ones give you up to 500 Tweets per request, you will lose some. I recommend to use the other API to set everything up and test it. Once it works, upgrade the API you want to use and switch to it.
High costs
30-days has a higher starting price, but lower costs per Tweet. It starts at $149 per month for 500 requests à 500 Tweets and goes up to $2,499 for 10k requests à 500 Tweets. One request costs nearly 30 Cent in the cheapest and about 25 Cent in the highest tier. Something like 0.06 to 0.05 Cent per Tweet.
Full Archive starts at $99 for 100 requests à 500 Tweets and goes up to $1,899 for 2500 requests. Resulting in $1 to $0.8 per request and 0.2 to 0.15 Cent per Tweet.
Because you have to pay each request, even if it doesn’t give you 500 Tweets and always pay the full tier, your real costs will be higher than a simple Tweets*$0.002 calculation.
Another problem is the uncertainty how many Tweets there are. If the topic you are interested got into the trends, you may have a number how many Tweets there were at that moment. But if you look at a longer time frame that won’t help much. The Twitter API always gives you Tweets from the newest date to the oldest. You can either upgrade to the first tier and let it run as far as it goes or you start with a sample and guesstimate from there how many Tweets there are.
Because of the high cost of ¢30 to $1 per request the Premium API is a quite expensive learning environment. If you misconfigure it, you can lose around $60 per minute. At least you will be limited by your current tier.
Fast data collection
While the Standard API can take days or even weeks to collect the data you need, the Premium API returns up to 5k Tweets per second, 30k Tweets per minute, 1.8M per hour.
Sign up early
While everyone with a Twitter account was able to create apps in the past, now you need to apply for a developer account. I can’t say much about it from my own experience because as far as I know the process changed since I went through it some years ago. I heard from some people that they never were approved, for others it took several weeks and some got approved within hours.
Be sure to read the Developer Policy and Agreement to know if the project you are planning doesn’t break them. Be honest in the application and make sure the Twitter account you are applying with doesn’t break any other Twitter terms.
Once you got your developer account, you can proceed with the next step.
1 Setup your development environment
I like to work with Jupyter Notebooks, because I can run code blocks independently from each other. Easiest way to install and maintain it on Windows is Anaconda. I will explain the next steps with Jupyter in mind, but you can code and run them however you want. In VS Code, in the CLI or anywhere else where Python runs.
1.1 Start Jupyter and create a new Python 3 notebook
You can start Jupyter through Anaconda or directly (enter Jupyter in your Search Bar). Jupyter will open in your browser and you can create a new Python 3 notebook with the button on the right side. I like to immediately rename the newly created notebook.
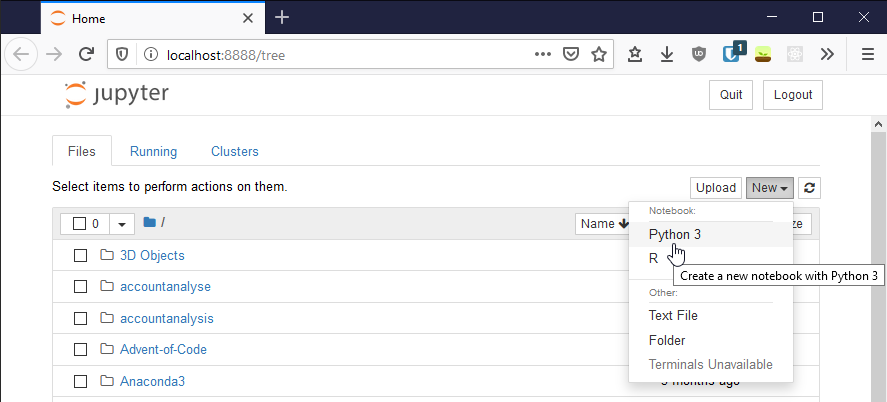
1.2 Install searchtweets
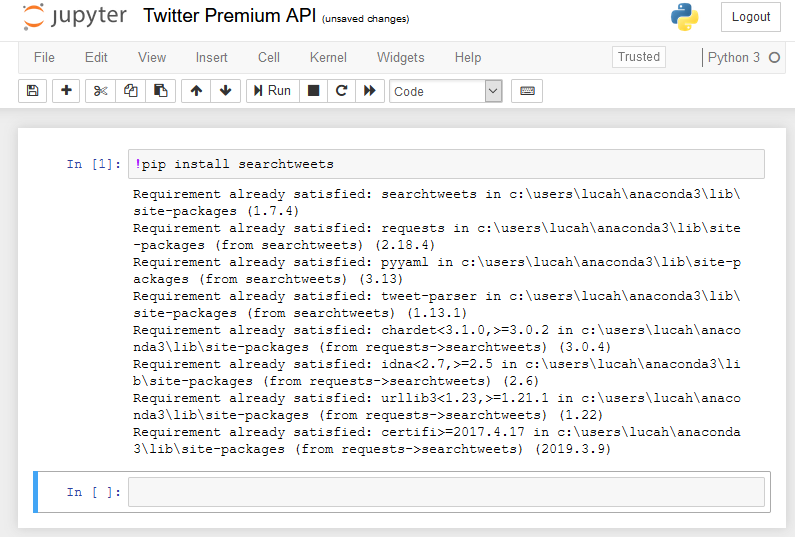
Twitter created a wrapper for the Premium API that we can use. You only have to install it with pip. If you use a Jupyter notebook the easiest way is to enter !pip install searchtweets and run it. If you use a console, you don’t need the exclamation mark.
Your output will look slightly different than mine, because I already had it installed.
1.3 Create app and connect it to the Premium API subscription
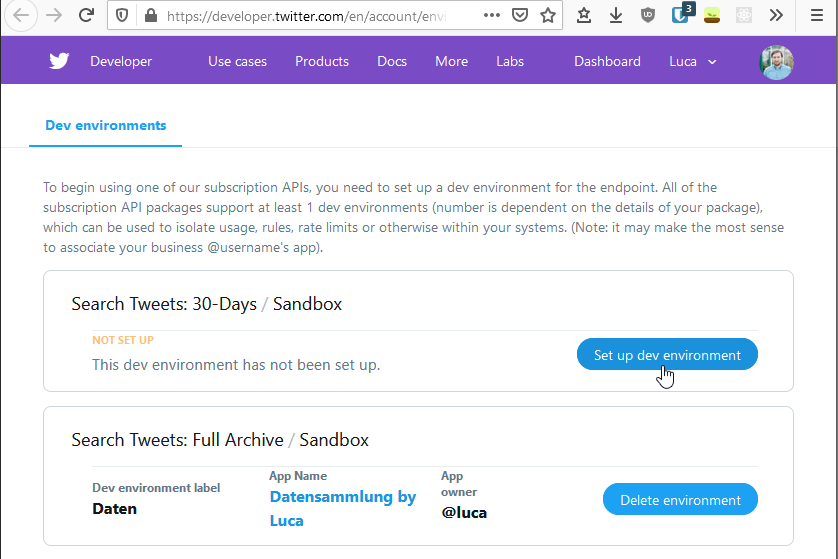
Twitter Premium API subscription is always connected to an app. So you need to create an app first.
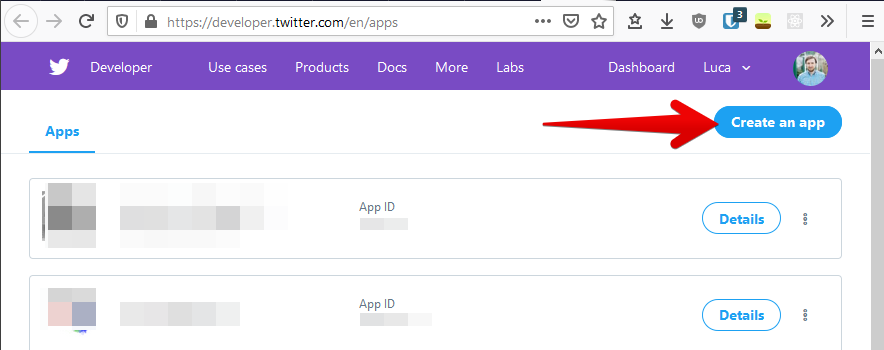
After you created the app, you set up the Dev environment for your subscription. You can choose any label you want, but it will be part of your endpoint. Choose something simple, you will recognize and can easily enter.
1.4 Save credentials to YAML file
Now we can create a file with the credentials. If you want, you can write it manually, but I will use Python for it. Be aware that it is bad practice to have credentials in your code. If you use any kind of version control, be sure to remove the credentials from the code before you check it in.
The credentials file, which we will save in the YAML format, will consist of four pieces of information. The account_type, the endpoint (with the label you chose before) and the consumer_key and consumer_secret of the app you created.
import yaml
config = dict(
search_tweets_api = dict(
account_type = 'premium',
endpoint = 'https://api.twitter.com/1.1/tweets/search/30day/YOUR_LABEL.json',
consumer_key = 'YOUR_CONSUMER_KEY',
consumer_secret = 'YOUR_CONSUMER_SECRET'
)
)
with open('twitter_keys_30days.yaml', 'w') as config_file:
yaml.dump(config, config_file, default_flow_style=False)
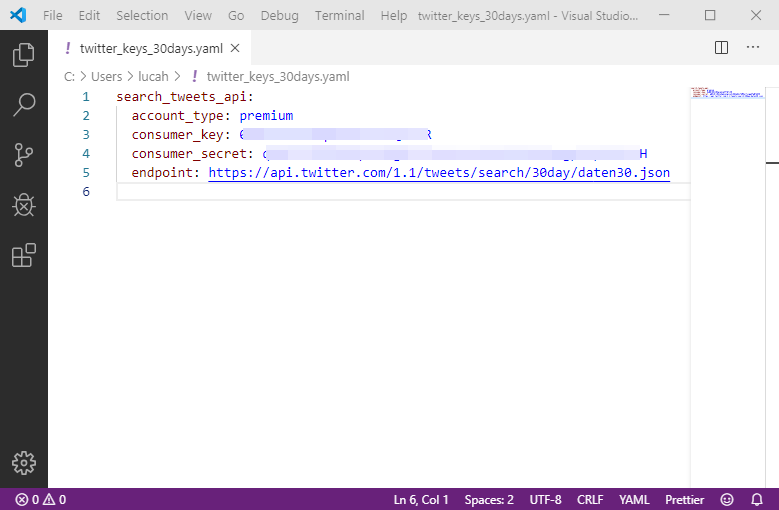
If you open the resulting file with a code editor, it will look like this. As you can see, it is very readable and you could easily create and edit manually if you want or need to.
2 Collect Tweets
Everything up to this point is only needs to be done once. The following steps are performed each time you use the Twitter Premium API.
2.1 Load credentials
We import the load_credentials function from searchtweets, tell it the filename and key (you could save multiple credentials to one file), then it creates the bearer token for us.
from searchtweets import load_credentials
premium_search_args = load_credentials("twitter_keys_30days.yaml",
yaml_key="search_tweets_api",
env_overwrite=False)
print(premium_search_args)
2.2 Define search rule
If you haven’t played around with the Twitter search, now is the time. Go to the browser and try to create the appropriate search query for your project. I wrote an Advanced Twitter Search Guide and contributed to this wonderful resource with Twitter search commands. You may want to read the official documentation of the Twitter Premium search API as well. Some operators are different for the Premium API and not all operators are available in the free sandbox tier, but only for paid tiers. See the official list of Premium operators.
The most important difference to the Twitter web search is that you define from_data and to_date as separate parameters and that you can not only define the date, but hour and minute as well.
The other parameter is results_per_call, which is 100 per default. If you use the sandbox tier, you don’t need to change it, but if you use a paid tier, change it to 500 or you will only get a fifth of what you pay for.
from searchtweets import gen_rule_payload
rule = gen_rule_payload("from:luca",
results_per_call=100#,
#from_date="2019-10-25 07:15",
#to_date="2019-11-04 23:11"
)
2.3 Create result stream
You could choose the simple road and get all results at once, but I assume that you use the Premium API to get bigger amounts of Tweets. But even if you only collect a small dataset, I recommend to use the result stream. When the results are streamed, you can save them while you receive them. If there is any problem (maybe you have to cancel or your internet has hiccups) all results you already received are saved. If you get them at once, they are lost. And you have to pay again, to receive them a second time.
I like to print the set up result stream to check it before I start it. In the example I use max_results of 100. Because of that I will only use one request. You want to set it way higher, once everything works. This is just another fail safe. In the paid tiers use multiples of 500.
from searchtweets import ResultStream
rs = ResultStream(rule_payload=rule,
max_results=100,
**premium_search_args)
print(rs)
2.4 Start the stream and save the results
Finally, we are ready to collect the Tweets. The script saves the full json objects it receives in a file. One per line. The file is then called a jsonl or json-lines.
To see how far we are, the script outputs the date of every tenth Tweet. This number is way too low. I normally use something like 5000. It helps me to see how many Tweets there are while the script runs.
import json
with open('twitter_premium_api_demo.jsonl', 'a', encoding='utf-8') as f:
n = 0
for tweet in rs.stream():
n += 1
if n % 10 == 0:
print('{0}: {1}'.format(str(n), tweet['created_at']))
json.dump(tweet, f)
f.write('\n')
print('done')Code as script
To make it easier to use, I compiled all the code into a small script that you can use directly and add to your research to make it easier to reproduce.
At the top of the script you will find 11 variables, that you have to adapt to your needs before you can run it. If you share the script, don’t forget to remove your credentials.
API_KEY = ''
API_SECRET_KEY = ''
DEV_ENVIRONMENT_LABEL = ''
API_SCOPE = '30day' # 'fullarchive' for full archive, '30day' for last 31 days
SEARCH_QUERY = ''
RESULTS_PER_CALL = 100 # 100 for sandbox, 500 for paid tiers
TO_DATE = '2019-11-04 23:11' # format YYYY-MM-DD HH:MM (hour and minutes optional)
FROM_DATE = '2019-10-25' # format YYYY-MM-DD HH:MM (hour and minutes optional)
MAX_RESULTS = 100000 # Number of Tweets you want to collect
FILENAME = 'twitter_premium_api_demo.jsonl' # Where the Tweets should be saved
# Script prints an update to the CLI every time it collected another X Tweets
PRINT_AFTER_X = 1000
#--------------------------- STOP -------------------------------#
# Don't edit anything below, if you don't know what you are doing.
#--------------------------- STOP -------------------------------#
import yaml
config = dict(
search_tweets_api=dict(
account_type='premium',
endpoint=f"https://api.twitter.com/1.1/tweets/search/{API_SCOPE}/{DEV_ENVIRONMENT_LABEL}.json",
consumer_key=API_KEY,
consumer_secret=API_SECRET_KEY
)
)
with open('twitter_keys.yaml', 'w') as config_file:
yaml.dump(config, config_file, default_flow_style=False)
import json
from searchtweets import load_credentials, gen_rule_payload, ResultStream
premium_search_args = load_credentials("twitter_keys.yaml",
yaml_key="search_tweets_api",
env_overwrite=False)
rule = gen_rule_payload(SEARCH_QUERY,
results_per_call=RESULTS_PER_CALL,
from_date=FROM_DATE,
to_date=TO_DATE
)
rs = ResultStream(rule_payload=rule,
max_results=MAX_RESULTS,
**premium_search_args)
with open(FILENAME, 'a', encoding='utf-8') as f:
n = 0
for tweet in rs.stream():
n += 1
if n % PRINT_AFTER_X == 0:
print('{0}: {1}'.format(str(n), tweet['created_at']))
json.dump(tweet, f)
f.write('\n')
print('done')Of course, you can use the Twitter Premium API directly through the searchtweets library by Twitter. Especially if you want to use it from the CLI, it offers much more functionality.
What’s next?
Done. You successfully collected Tweets from the Twitter Premium API. You now have a nice jsonl-file with all the Tweets. In the next article I will show you, how you can load those Tweets from the file and create a dynamic Retweet network.
Thanks a lot, man!
Great instructions! Thank you.
Is it possible to save the data as a normal .json? I’m having difficulties loading the jsonlines into one dataframe (in order to run some analysis).
My code:
“with open(‘twitter_premium.json’, ‘w’) as json_file:
json.dump(rs.stream, json_file)”
Gives the following error:
“raise TypeError(f’Object of type {o.__class__.__name__} ‘
TypeError: Object of type method is not JSON serializable”
If you use the collect_results function instead of ResultStream, you can load all results at once and then dump them into a json-file.
I did not test this code:
from searchtweets import collect_results tweets = collect_results(rule, max_results=100, result_stream_args=premium_search_args with open('twitter_premium.json', 'w') as json_file: json.dump(tweets, json_file)I advice against doing so, because you will loose all data you received when something goes wrong. By writing everything to the jsonlines file, you can fix the error and continue data collection instead of starting new. I suggest that you rather try to find a way to get jsonlines into a dataframe.
I use the following function to get jsonlines into a dataframe:
import pandas as pd import json_lines def load_jsonl(file): tweets = [] with open(file, 'rb') as f: for tweet in json_lines.reader(f, broken=True): tweets.append(tweet) return (tweets) tweets = load_jsonl('twitter_premium_api_demo.jsonl') df = pd.DataFrame(tweets)This has the benefit that you can discard data while reading it. I am explaining this a bit more in my tutorial about Retweet-Networks. The first few paragraphs are relevant to your question.
If you don’t need to prepare the data, you can use the read_json function of pandas and tell it, that it’s a jsonlines file.
df = pd.read_json('data.json', lines=True)hi can anyone please let me know how to approve the request for free twitter developer key? I have tried two times and they have rejected my request. I need to access the key in order to collect the data set for my PHD research
Hi Luca,
Thank you so much for the instruction! Yours is the best I found on the Internet!
Thanks to you, I was able to get the bearer_token, set the rule, and I thought I am all set. For your reference, below is the response I get for print(rs):
++++++++++++++++
ResultStream:
{
“username”:null,
“endpoint”:”https:\/\/api.twitter.com\/1.1\/tweets\/search\/fullarchive\/TwitterInfoTest.json”,
“rule_payload”:{
“query”:”COVID”,
“maxResults”:100
},
“tweetify”:true,
“max_results”:100
}
+++++++++++++++++++
But, I am getting “HTTP Error code: 403: Forbidden: Authentication succeeded but account is not authorized to access this resource.” when I run the following codes:
+++++++++++++++
import json
with open(‘twitter_premium_api_demo.jsonl’, ‘a’, encoding=’utf-8′) as f:
n = 0
for tweet in rs.stream():
n += 1
if n % 10 == 0:
print(‘{0}: {1}’.format(str(n), tweet[‘created_at’]))
json.dump(tweet, f)
f.write(‘\n’)
print(‘done’)
++++++++++++++++++++++++
I have set up a full archive sandbox account (Search Tweets: Full ArchiveSandbox). From my understanding, even if I didn’t subscribe to a paid premium API, I should be able to test using the sandbox.
Any advice would be a huge help. I am searching all over but cannot find an answer..
Thank you in advance!
Hi Luca,
thanks for this! very clear elaboration.
I am new to the premium (sandbox) api and I am wondering how I can add more attributes to the search output (e.g. coordinates)?
If the Tweet has an location attached to it, the coordinates will already be present. The paid Premium API has some additional location enrichment like matching the location to a city/country.
Fantastic instructions!
Do you know how I put an emoji in the query? for example:
gen_rule_payload(“@twitter :)”,
results_per_call=100#,
#from_date=”2019-10-25 07:15″,
#to_date=”2019-11-04 23:11″
)
I’ve also tried:
gen_rule_payload(“@twitter \”:)\””,
results_per_call=100#,
#from_date=”2019-10-25 07:15″,
#to_date=”2019-11-04 23:11″
)
Hi there Luca, I am able to run everything smoothly thanks for all your instructions!!!
However, my eventual jsonl file, which I converted to a dataframe using the pd code you provided, is empty. Obviously I think this is because the jsonl file itself is empty.
Any thoughts on why this might be? I’ve included the code below
API_KEY = ‘copied mine here’
API_SECRET_KEY = ‘copied mine here’
DEV_ENVIRONMENT_LABEL = ‘copied mine here’
API_SCOPE = ‘fullarchive’ # ‘fullarchive’ for full archive, ’30day’ for last 31 days
SEARCH_QUERY = ‘HistTest’ #I assumed we could just come up with a name for this?
RESULTS_PER_CALL = 100 # 100 for sandbox, 500 for paid tiers
TO_DATE = ‘2019-11-04 23:11’ # format YYYY-MM-DD HH:MM (hour and minutes optional)
FROM_DATE = ‘2019-10-25’ # format YYYY-MM-DD HH:MM (hour and minutes optional)
MAX_RESULTS = 100000 # Number of Tweets you want to collect
FILENAME = ‘twitter_premium_api_tweetest.jsonl’ # Where the Tweets should be saved
# Script prints an update to the CLI every time it collected another X Tweets
PRINT_AFTER_X = 1000
#————————— STOP ——————————-#
# Don’t edit anything below, if you don’t know what you are doing.
#————————— STOP ——————————-#
import yaml
config = dict(
search_tweets_api=dict(
account_type=’premium’,
endpoint=f”https://api.twitter.com/1.1/tweets/search/{API_SCOPE}/{DEV_ENVIRONMENT_LABEL}.json”,
consumer_key=API_KEY,
consumer_secret=API_SECRET_KEY
)
)
with open(‘twitter_keys.yaml’, ‘w’) as config_file:
yaml.dump(config, config_file, default_flow_style=False)
import json
from searchtweets import load_credentials, gen_rule_payload, ResultStream
premium_search_args = load_credentials(“twitter_keys.yaml”,
yaml_key=”search_tweets_api”,
env_overwrite=False)
rule = gen_rule_payload(SEARCH_QUERY,
results_per_call=RESULTS_PER_CALL,
from_date=FROM_DATE,
to_date=TO_DATE
)
rs = ResultStream(rule_payload=rule,
max_results=MAX_RESULTS,
**premium_search_args)
with open(FILENAME, ‘a’, encoding=’utf-8′) as f:
n = 0
for tweet in rs.stream():
n += 1
if n % PRINT_AFTER_X == 0:
print(‘{0}: {1}’.format(str(n), tweet[‘created_at’]))
json.dump(tweet, f)
f.write(‘\n’)
print(‘done’)
import pandas as pd
import jsonlines
def load_jsonl(file):
tweets = []
with open(file, ‘rb’) as f:
for tweet in jsonlines.Reader(f):
tweets.append(tweet)
return (tweets)
tweets = load_jsonl(‘twitter_premium_api_demofile.jsonl’)
df = pd.DataFrame(tweets)
df.head() # output shows a blank line
Again the output of the first cell simply runs in one second and prints “done” it doesn’t print any sample lines.
then in the second cell the output of the header is a blank line and the pd.shape is 0,0
thank you for any help you can provide, basically I believe the code is being authenticated by twitter but is not returning anything through the result stream.
The problem is most likely your query. That’s not the name of the project, but the actual search query. The script will only retrieve Tweets, that match that query. You used ‘HistTest’. But in the specified time frame no Tweets with that term were published: https://twitter.com/search?q=histtest%20from%3A2019-10-25%20until%3A2019-11-04&src=typed_query&f=live.
You should try with a different query or time frame.
Hi Luca not sure if my last post went through. I have completed all the steps with your super helpful instructions, everything is authenticating with the endpoint, but the json file does not seem to be pulling in any tweet objects. when I convert to a pd.dataframe per your (also super helpful!) instructions above, the header and shape show the df as empty. Is there a reason no “tweet” objects are populating my json file? I see the file is created, but it is 0 bytes by the way. Any help or tutoring much appreciated!!! I’m an academic research teacher in case this gives more context.
Hi Luca,
I used your code to successfully collect historical tweets from about 100 users with relatively few tweets. But it seems that if the user has more than 5,000 tweets, the code returns 50 tweets or less. Is there something that I’m doing wrong?
Thanks!
Hi Luca,
thank you so much for your Tutorial, it is very helpful.
I am trying to collect a large amount of tweets and only receive approx. 1000 tweets each time running the code. Do you know how how to automate running the code?
Thanks!
If you run the script on a Linux machine, I would recommend setting up a cron job.
How we can implement “Pagination”. If we want to apply the concept of next_token?
Hello Luca,
I have used the code you provided and was successful to collect a large amount of data. However, the tweets that are more than 148 characters, are not getting fully downloaded. There is “…” at the end of every larger tweet. I am using full archive paid tier. Do you have any solution for that?
That’s weird. The Standard API 1.1 had a 140 character limit per default and a extended_tweet parameter to get more, but the Premium API should always return the full text. There isn’t even a parameter to change that.
Could it be a issue with how you display the Tweets? Can you look at the jsonl-file with a code editor?
Hi Luca,
thank you so much for your really helpful code! It saved me some grey hair 😉
I have used the code you provided and it worked! How would I have to edit the code, so that it runs automatically and loops through the collection of the Tweets. I came so far to understand, that I might need a next_token? It would be of so much great help, if you could elaborate on that.
A desparate Master’s student.